내가 판 100 페이지 논문리뷰 무덤..
땅파러 간다
Abstract
GPT-4는 이미지와 텍스트 입력을 받고 텍스트 출력을 생성할 수 있는 large-scale multimodal 모델이다. 여러 학문적인 벤치마크에서 인간 수준의 성능을 출력함. (시험 점수 상위 10%, 변호사 시험 통과) Pre-trained 된 Transformer 모델이다. Post-training alignment process results를 통해서 사실성과 원하는 동작에 대한 성능이 향상됨. 이 Report는 GPT-4의 계산량의 1/1000 이상의 모델로 훈련된 결과를 기반으로 함.
1. Introduction
이 레포트에서 강조하는 것 : 이미지와 텍스트 입력 처리, 텍스트 출력 생성이 가능한 대규모 멀티모달 모델이라는 점. 이러한 모델은 대화 시스템, 텍스트 요약, 기계 번역 등 다양하게 사용될 수 있음.
인간을 대상으로 설계된 다양한 시험에서 테스트를 진행한 결과, GPT-4는 상위 10퍼센트에 해당하는 점수를 얻었다. (GPT-3.5의 경우에는 하위 10퍼센트)
기존의 NLP 벤치마크 세트에서 이전 대규모 언어모델들을 능가한다. MMLU 벤치마크에서는 57개의 주제를 다루는 영어로 된 다중 선택 질문 세트로, GPT-4는 영어 뿐 만 아니라 다른 언어에서도 강력한 성과를 보임. (26개의 언어 중 24개의 언어에서 영어 기준 최고 성능 능가)
그러나 이전 GPT 모델들과 같이 유사한 제한 사항을 가지고 있음. 얘를 들어 hallucination 즉 환각이 여전히 발생할 수 있어 완전히 신뢰해서는 안된다. (= 자기 멋대로 결과를 출력하는 경우)
그래서 이 페이퍼에서는 이러한 잘못된 정보, 과도한 의존, 개인정보 보호, 사이버 보안, 확산등에 대한 피해를 완화하기 위해 제작자들이 취한 행동에 대해서도 설명되어 있음. (뒤쪽 system card 참고)
2. Scope and Limitation of this Technical Report
이 레포트는 GPT-4의 능력, 한계, 안전에 초점을 맞췄다. 그래서 아키텍쳐, 하드웨어, training computes, 데이터셋, 훈련 방법에 대한 추가적인 세부 정보에 대해서는 포함 X (이미지 인풋 기술볼라고 햇는데 망함 ㅋㅋ)
3. Predictable Scaling
이 프로젝트의 주요 초점은 예측 가능한 확장성을 갖는 딥러닝 스택을 구축하는 것이다. 매우 큰 규모의 training run에서는 광범위한 모델 별 조정을 수행하는 것이 거의 불가능 하기 때문에, 이를 위해서 여러 규모에서 예측 가능한 동작을 갖는 인프라와 최적화 방법을 개발. 이를 통해 1000배에서 10000배 더 적은 계산을 사용하여 훈련된 작은 모델을 기반으로 이 GPT-4의 성능 일부 측면을 예측.
3.1 Loss Prediction
적절하게 훈련된 대형 언어 모델의 final loss는 훈련에 사용된 계산량의 제곱 법칙으로 well approximated될 것이다. 저자는 최적화 인프라의 확장성을 검증하기 위해 더이상 줄일 수 없는(?) loss를 포함한 스케일링 법칙을 적용하여 내부 코드 베이스에서 최종 loss를 예측했다.
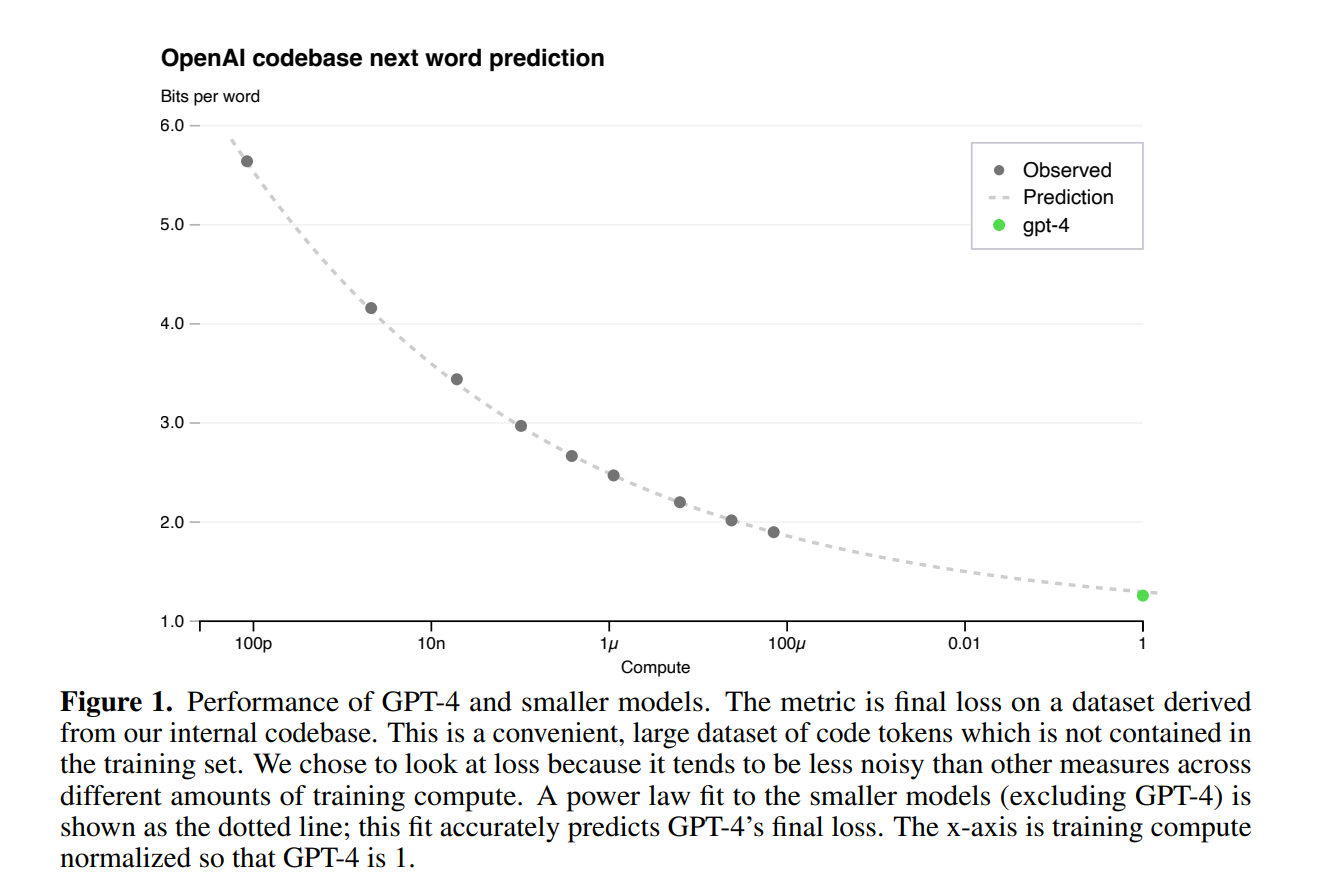
Power law (멱 법칙 혹은 베키의 법칙) : 한 수가 다른 수의 거듭 제곱에 반비례 하여 나타남.
3.2 Scaling of Capabilities on HumanEval
훈련 전에 모델의 능력을 알 수 있게 되면 정렬, 안전성 및 배포에 대한 결정을 개선할 수 있다. Final loss를 예측하는 것 외에도, 능력의 해석 가능한 측정 항목을 예측하기 위한 방법론을 개발함. 그 중 하나가 다양한 복잡도를 가진 파이썬 함수를 합성하는 능력으로 측정하는 HumanEval 데이터셋에서의 통과율이다. Small model에서 이 통과율을 추정하여 성공적으로 예측했다.
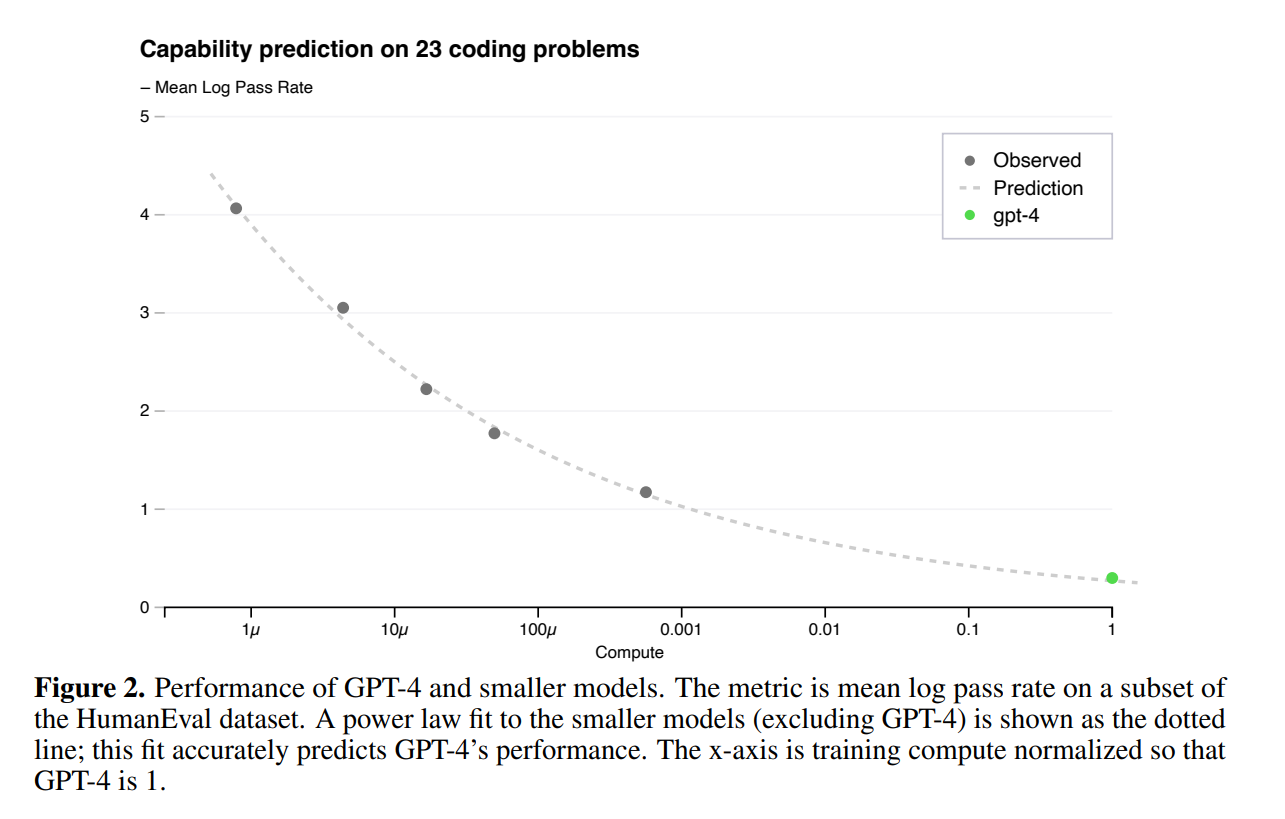
HumanEval의 개별 문제의 경우, 때때로 규모가 커질 수록 성능이 악화될 수 있다. 그러나 이러한 문제를 극복하기 위해서 근사적인 멱 법칙 관계를 발견하고, 이 관계가 이 데이터셋의 모든 문제에 적용된다고 가설을 세웠다.
GPT-4의 HumanEval 성능에 대한 예측은 훈련이 완료되기 전에 사용 가능한 정보만을 사용하여 기록되었다. 가장 어려운 15개의 HumanEval 문제를 제외한 나머지 문제들은 작은 모델의 성능을 기반으로 6개의 난이도 버킷으로 분류되었다. 3번째로 쉬운 버킷에서의 결과가 그림 2에 나와있고, 이 결과는 작은 모델들의 log(pass_rate)를 정확하게 추정할 수 있는 HumanEval 문제 하위집합에서 매우 정확한 예측을 보여줬다. 다른 다섯개의 버킷에서도 역시 예측이 동일하게 수행되었으며, 가장 쉬운 버킷에서 GPT-4의 예측보다 성능이 낮았던 것만이 예외이다.
일부 능력은 예측하기 어렵다. 예를 들어 Inverse Scaling Prize는 모델 성능이 규모의 함수로 감소하는 여러 작업을 제안했다. 최근 연구결과와 유사하게 GPT-4가 이러한 경향을 뒤집는 다는 것이 발견되었다.

저자는 정확한 예측이 안전에 중요하다고 생각하기 때문에 추후에도 이러한 방법을 개선하고 대규모 모델 훈련이 시작되기 전에 다양한 능력에 대한 성능 예측을 등록할 것이며, 이것이 일반적인 목표가 되기를 희망한다고 한다.
4. Capabilities
GPT-4는 기존의 사람들을 위해 설계된 시험을 통해 여러가지 벤치마크에 대해 테스트되었다. (따로 train 안함) 시험 문제중 일부는 모델이 훈련중에 접하긴 했으나 각 시험에 대해 해당 문제들을 제거한 변형 버전으로 테스트를 실행하고 두 점수 중 낮은 점수를 보고했다.
시험에는 객관식과 주관식 문제가 포함되어 있으며, 각 형식에 맞는 별도의 프롬프트를 설계하여 필요한 경우 이미지가 입력에 포함되었다. 평가 설정은 시험의 검증 세트에서의 성능을 기반으로 설계. 전반적인 점수는 각 시험에 대해 공재적으로 제공되는 methodologies(방법론)을 사용하여 객관식 문제와 주관식 문제의 점수를 결합하여 결정되었다. 각 전반적인 점수에 해당하는 백분위수를 추정하고 보고함.

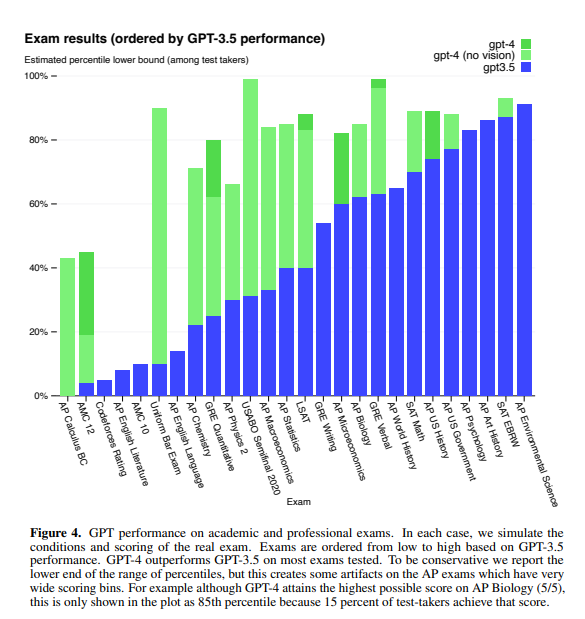
4.1 Visual Inputs
GPT-4는 이미지와 텍스트로 구성된 프롬프트를 받아들이며, 이는 텍스트만 있는 설정과 병렬로 사용돼서 사용자가 시각적, 언어적 작업을 지정할 수 있도록 한다. 구체적으로 설명하자면, 모델은 임의로 교차되는 텍스트와 이미지로 구성된 입력을 받아 텍스트 출력을 생성한다. 텍스트와 사진, 다이어그램 또는 스크린샷이 포함된 문서와 같은 다양한 도메인에서 GPT-4는 텍스트만 있는 입력과 유사하게 작동한다. 언어 모델을 위해 개발된 standard test-time techniques(ex : few-shot prompting, chain-of-thought 등)은 이미지와 텍스트를 함께 사용할 때도 유사하게 효과적이다.
추가적인 내용은 GPT-4 (openai.com) GPT-4 블로그에서 볼 수 있음.

(내용 너무 없어서 Appendix image 설명 부분 추가)
A4. Images
시험 문제에는 종종 이미지가 포함될 수 있다(다이어 그램이나 표와 같은). 입력을 텍스트로만 받는 GPT-3.5와 같은 모델은 이미지가 없는 경우에는 모든 정보에 접근할 수 없을 수 있다. 다중 선택 문제에서 텍스트 모델을 평가할 때는 이미지가 누락 된 경우에 IMAGE : 와 같이 의미없는 파일 이름을 나타내는 텍스트 태그를 추가함. 이를 통해 텍스트 기반 모델의 다중 선택 시험 성능의 하한을 구할 수 있었다. 멀티모달 모델을 다중 선택 문제에서 평가할 때는 이미지를 프롬프트에 포함시킴. SAG Reading and Writing, MKSAP, Sommelier, AP Psychology, AP English Language, AP English Literature 시험의 다중 선택 섹션에는 이미지가 포함되지 않는다. 모든 주관식 문제와 USABO 2020 semifinal의 경우 이미지와 도표를 전사(transcription)하였다. 이를 통해 주관식 답변을 평가하는데 필요한 수작업 grading 작업을 줄임. 이 전사 과정 이후에는 주관식 프롬프트에 이미지가 없었다.


놀랍게도 GPT-4 안에 있는 visual input 내용은 이게 다다............. 너무 놀라워
(뒤에 system card 파트쪽에 이미지 내용이 있긴한데 이쪽은 안전성이나 위험 방지 내용이여서 참고만)
물론 OpenAI 쪽에서는 DALL-E 2가 있긴 하지만 그건 이미지 생성쪽이지 이미지 입력쪽은 아니니까... 어느정도 모델 구조를 공개할거라고 생각했음...
참고로 GPT-4는 이미지 생성은 불가능
+ 참고로 gpt 4 라이브 방송에서 디스코드의 스크린 샷을 인풋으로 넣고 돌렸는데
4분정도의 시간 뒤에 매우 정확하고 자세한 내용이 출력되었다고 함.
거의 모든 단일 요소를 잡아내고, 서버이름, 음성 채널, 심지어 모든 구성원 이름을 잡아냄.
다른 파트는 시간날때 보거나 정리하겠습니다..



