Abstract
이 논문에서는 음성 처리 시스템의 능력을 연구하였다. 68만 시간의 다국어 및 다작업 supervision을 적용한 결과, 일바적인 벤치마크에서 잘 일반화되면서 다른 모델들과의 경쟁력을 갖지만 어떠한 파인튜닝도 필요하지 않은 제로샷 transfer setting에서 작동한다. 정확도와 견고성(robust)을 올리고, 이 모델의 추론코드를 공개하여 견고한(robust) 음성 처리에 대한 추가적인 연구의 기반으로 활용되고자 한다.
1. Introduction
음성인식 분야의 발전은 Way2Vec 2.0과 같은 unsupervised pre-training techniques (비지도 사전 훈련 기법)의 개발로 인해 활기를 얻었다. 이 방법은 인간이 직접 라벨을 작성할 필요 없이 날것의 오디오에서 직접 학습하기 때문에 라벨이 없는 음성 데이터셋을 생산적으로 활용할 수 있으며, 1,000,000시간 이상의 훈련 데이터를 빠르게 확장할 수 있다. 이러한 접근 방식은 표준 벤치마크에서 파인튜닝된 결과로 최신 기술 수준을 향상시키고, 특히 데이터가 적은 경우 효과적이다.
이러한 pre-trained된 오디오 인코더는 고품질 음성 표현을 학습하지만 완전히 비지도 학습이기 때문에 해당 표현을 실제 음성인식과 같은 작업에 매핑해주는 등의 동등한 수준의 성능을 갖는 디코더가 부족하여 실제 작업 수행을 위해서는 파인튜닝이 필요하다. 하지만 파인튜닝의 경우 추가적인 위험이 존재한다. Radford는 Imagenet 데이터셋에서 컴퓨터 비전 모델을 파인튜닝할 때 객체 분류 정확도가 약 10퍼센트 증가하는 것을 문서화했으나, 동일한 객체를 다른 일반 이미지 데이터셋 7개에서 분류할 때 평균 정확도에는 개선이 없었다. 즉 특정 데이터셋에서 훈련된 모델이 엄청난 성능을 달성할 수 있지만 다른 데이터셋에서 평가할 때는 기본적인 오류를 발생할 수 있다는 소리.
이는 비지도 사전 훈련이 오디오 인코더의 품질을 현저하게 향상시켰지만, 동등한 품질의 사전 훈련된 디코더가 부재하고, 데이터셋 특정 파인튜닝을 권장하는 프로토콜의 결합은 모델의 유용성과 견고성을 제한하는 강력한 약점이다. 음성 인식 시스템의 목표는 지도없이 "별도의 설정 없이(out of the box)" 다양한 환경에서 신뢰성 있게 작동하는 것이다. Likhomanenko et al. (2020) 및 Chan et al. (2021)의 연구에 따르면, 다양한 데이터셋이나 도메인에서 supervised 방식으로 사전 훈련된 음성 인식 시스템은 단일하게 훈련된 모델보다 높은 견고성을 가지고 보유 데이터셋에 대해 훨씬 효과적으로 일반화된다. 이러한 연구들은 가능한 많은 기존 고품질 음성 인식 데이터셋을 결합함으로써 이를 달성한다. (SpeechStew의 경우 5140시간의 supervised 데이터를 포함하는 7개의 기존 데이터셋을 혼합했지만, 앞에서 말한 1,000,000시간의 unsupervised 음성 데이터와 비교했을땐 여전히 매우 작은 규모.)
기존 고품질 지도 데이터셋의 한계를 인식해서 최근의 연구들은 더 큰 데이터셋을 만들어내고 있다. (예시 : Chen et al. (2021)과 Galvez et al. (2021), 컴퓨터 비전 연구에서 ImageNet과 같은 지도데이터셋 사용)
하지만 이러한 새로운 데이터셋은 기존의 고품질 데이터셋의 합보다는 몇 배 크지만, 이전의 비지도 학습 작업보다는 훨씬 작다. 이 논문에서는 이러한 간극을 해소하기 위해서 약간의 supervised 음성 인식을 680,000 시간의 레이블된 오디오 데이터로 확장. 이 접근법을 Whisper 2라고 부른다. 저자는 이 규모에서 훈련된 모델이 기존의 데이터셋에 대해
zeroshot으로 전이되어 고품질 결과를 얻기위해 어떠한 데이터셋에 대한 파인튜닝도 필요하지 않음을 보여준다. 이 연구는 영어에 국한되지 않고 다중 언어 및 다중 작업을 포괄하는 사전 지도훈련의 범위를 확장하는 데도 초점을 맞춘다. 이 680,000 시간의 오디오 중 117,000 시간은 다른 96개의 언어를 커버한다. 또한 데이터셋에는 125,000 시간의 X→En 번역 데이터가 포함되어 있다.
이 연구는 음성 인식에서 약간의 사전 지도 훈련의 간단한 스케일링이 현재까지 충분히 인정받지 못한 것을 시사한다. 저자는 최근의 대규모 음성 인식 작업의 주요 기법으로 사용된 self-supervision또는 자체 훈련 기술 없이 이러한 결과를 달성한다. 또한 견고한 음성 인식에 대한 추가 연구를 기반으로 깃허브에 추론코드와 모델을 공개한다.
2. Approach
2.1 Data Processing
인터넷에서 대규모 텍스트를 기계 학습 시스템 훈련에 활용하는 최근 연구의 흐름을 따라, 저자는 데이터 전처리에 대한 최소주의적 접근을 취한다. 많은 음성 인식 작업과는 대조적으로 Whisper 모델을 일반화된 형식이 없는 날것의 텍스트 예측에 훈련시킨다. Seq2Seq 모델의 표현 능력에 의존하여 발화와 해당 발화의 전사(transcripts) 형식간의 매핑을 학습한다. 이는 자연스러운 전사를 생성하기 위해 별도의 역 텍스트 정규화 단계가 필요하지 않기 때문에 음성 인식 파이프라인을 단순화시킨다. 다양한 환경, 녹음 설정, 화자 및 언어의 넓은 분포를 가진 매우 다양한 데이터셋을 결과로 제공한다. 오디오 품질의 다양성은 모델의 견고성 훈련에는 도움이 될 수 있지만, 전사 품질의 다양성은 동일한 이점을 제공하지 않는다. 저자는 초기 검토에서 날것의 데이터셋에 품질이 낮은 전사가 많이 포함되어 있음을 확인하고, 전사 품질을 개선하기 위해 여러 자동 필터링 방법을 개발했다.
인터넷 상의 많은 전사는 실제로 인간이 생성한 것이 아니라 기존의 ASR(automatic speech recognition) 시스템의 출력이다. 최근 연구에서는 인간과 기계가 생성한 데이터가 혼합된 데이터셋으로 훈련하는 것이 번역 시스템의 성능을 저하시킨다고 밝혀졌다. "transcript-ese"를 배우는 것을 피하기 위해, 저자는 기계가 생성한 전사를 감지하고 제거하기 위한 다양한 heuristics을 개발. 많은 기존 ASR 시스템은 콤마, 물음표, 느낌표와 같은 복잡한 문장 부호, 단락과 같은 서식화된 공백, 대문자 사용과 같은 스타일 측면과 같이 오디오 신호만으로 예측하기 어려운 측면을 제거하거나 정규화하는 방식으로 작동한다. 모두 대문자 또는 소문자로 이루어진 전사는 인간이 생성한 것일 가능성이 매우 낮다. 많은 ASR 시스템은 일부 역 텍스트 정규화를 포함하지만, 일반적으로 간단하거나 rule-based이다. 또한 쉼표와 같은 처리되지 않은 다른 측면에서 감지될 수 있다.
또한 저자는 CLD2(=Compact language detector2)를 기준으로 텍스트와 일치하지 않는 경우에는 오디오, 전사쌍을 음성인식 훈련 데이터 예제로 포함시키지 않도록 하기 위해, VoxLingua107 데이터셋의 프로토타입 버전에서 훈련된 프로토타입 모델을 파인 튜닝한 오디오 언어 감지기를 사용한다. 두 가지가 일치하지 않는 경우, 해당 오디오, 전사 쌍을 데이터셋의 음성인식 훈련 예제로 포함시키지 않는다. 다만 전사 언어가 영어인 경우에는 이러한 쌍을 X→EN 음성 번역 훈련 예제로 데이터셋에 추가한다. 저자는 훈련 데이터셋에서 중복과 자동 생성 콘텐츠의 양을 줄이기 위해 fuzzy de-duping(흐린 중복 제거) 를 사용한다.
오디오 파일을 30초 세그먼트로 나누고 해당 시간 세그먼트 내에서 발생하는 전사의 하위 집합과 쌍을 이룬다. 저자는 음성이 없는 세그먼트를 포함한 모든 오디오로 훈련을 진행하며(확률적으로는 하위 샘플링을 사용), 이러한 세그먼트를 음성 활동 감지의 훈련 데이터로 사용한다.
추가적인 필터링 과정으로, 초기 모델을 훈련한 후에는 훈련 데이터 소스에서 오류율 정보를 종합하고 이러한 데이터 소스를 오류율과 데이터 소스 크기의 조합으로 정렬해서 수동으로 검사하여 저품질 데이터를 효율적으로 식별하고 제거한다. 이 검사에서는 부분적으로 전사된, 또는 정렬/미정렬이 잘못된 전사 뿐 만 아니라 필터링 휴리스틱이 감지하지 못한 저품질 기계 생성 캡션도 많이 발견되었다. 오염을 피하기 위해서 TED-LIUM 3(오디오 데이터셋)와 같이 중복이 발생할 가능성이 높다고 판단되는 평가 데이터셋과 훈련 데이터셋 간의 전사 수준에서 중복을 제거한다.
2.2 Model
이 연구의 초점은 대구모 지도 사전 훈련이 음성 인식에 미치는 능력을 연구하는데 있기 때문에, 모델 개선과 연구 결과의 혼동을 피하기 위해 기존의 아키텍쳐인 인코더-디코더 트랜스포머를 선택했다. 모든 오디오는 16,000Hz로 재 샘플링되며, 25-millisecond window stride로 80-channel 로그-폭 스펙트로그램 표현이 계산된다. 특징 정규화를 위해, 입력을 전체적으로 전처리 데이터셋을 기준으로 -1과 1 사이의 범위로 전역적으로 스케일링하고 평균이 거의 0이 되도록 한다. 인커더는 이 입력 표현을 처리하기 위하여 3개의 필터 너비를 가진 두 개의 합성곱 레이어로 구성된 작은 stem을 사용하며, 두 번째 합성곱 레이어는 스트라이드가 2이다. 사인 함수를 사용한 위치 임베딩이 스템의 출력에 추가되고, 이후 인코더 transformer 블록이 적용된다. 트랜스포머는 사전 활성화 잔차블록(=pre-activation residual blocks)을 사용하며, 인코더 출력에 최종적인 레이어 정규화가 적용된다. 디코더는 학습된 위치 임베딩과 입력-출력 토큰 표현을 고유한다. 인코덩와 디코더는 동일한 폭과 트랜스포머 블록 수를 가지고 있다. 그림 1에서 모델 아키텍쳐 요약을 볼 수 있다.

영어 전용 모델에는 GPT-2에서 사용된 바이트 수준 BPE(text tokenizer)와 동일한 것을 사용하며, 다국어 모델의 경우 다른 언어에서의 과도한 분할을 피하기 위해 어휘를 다시 맞추지만 GPT-2의 BPE 어휘는 영어 전용이기 때문에 언어에 따라 조정한다.
2.3 Multitask Format
특정 오디오 스니펫에서 발화된 단어를 예측하는 것은 전체 음성 인식 문제의 핵심 부분이며 많은 연구에서 광범위하게 연구되었지만, 이것이 유일한 부분은 아니다. 완전한 기능을 갖춘 음성 인식 시스템에는 음성 활동 감지, 화자 분리, 역 텍스트 정규화와 같은 많은 추가 구성 요소가 포함될 수 있다. 이러한 구성 요소는 종종 별도로 처리되어 핵심 음성 모델 주변에 비교적 복잡한 시스템을 만들어서, 이 복잡성을 줄이기 위해 단순히 핵심 인식 부분 뿐만 아니라 전체 음성처리 파이프라인을 수행하는 단일 모델을 갖는 것을 목표로 하였다. 동일한 입력 오디오 신호에서 수행할수 있는 다양한 작업은 전사(transcription), 번역(translation), 음성 활동 감지(voice activity detection), 정렬(alignment) 및 언어 식별(language identification) 등 몇 가지 예가 있다.
이러한 종류의 단일모델로의 일대다 매핑을 위한 작업 지정 형식이 필요하다. 저자는 작업과 조건 정보를 디코더의 입력 토큰 시퀀스로 간단히 지정하는 형식을 사용한다. 디코더가 오디오 조건화 언어모델이므로, 음성과 관련된 텍스트 히스토리에도 의존하도록 훈련시킨다. 이를 통해 모델이 모호한 오디오를 해결하기 위해 보다 긴 범위의 텍스트 컨텍스트를 사용하는 방법을 학습하도록 한다. 구체적으로 : 일부 확률로 현재 오디오 세그먼트 이전의 트랜스크립트 텍스트를 디코더의 컨텍스트로 추가한다. 예측의 시작을 나타내기 위해서 <|startoftranscript|> 토큰을 사용한다. 먼저 발화되는 언어를 예측하며, 훈련 세트에 있는 각 언어에 대한 고유한 토큰(총 99개)를 사용하여 표현한다. 이 언어 타겟은 앞에서 언급한 VoxLingua107 모델에서 가져온다. 오디오 세그먼트에 음성이 없는 경우, 모델은 이를 나타내는 <|nospeech|>토큰을 예측하도록 훈련된다. 다음 토큰은 작업(전사 또는 번역)을 지정하며, 또는 <|transcribe|> or <|translate|>으로 표시된다. 이후 타임스태프를 예측할 것인지 지정하기 위해 <|notimestamps|>토큰을 포함시킨다. 이 단계에서 작업과 원하는 형식이 완전히 지정되며, 출력이 시작된다. 타임 스태프 예측을 위해 현재 오디오 세그먼트를 기준으로 시간을 예측하며, 모든 시간을 20밀리초로 양자화하고 Whisper 모델의 기본 시간 해사도와 일치하도록 추가적인 토큰을 어휘에 추가한다. 타임스태프 예측을 캡션 토큰과 교차하여 수행한다. 시작시간 토큰은 각 캡션 텍스트의 앞에서 예측되며, 종료시간 토큰은 그 뒤에서 예측된다. 현재 30초 오디오 청크에 완전히 포함되지 않은 최종 트랜스크립트 세그먼트의 경우, 타임 스태프 모드에서 해당 세그먼트의 시작 시간 토큰만 예측하여 이후 디코딩이 해당 시간에 맞춰진오디오 창에서 수행되어야 함을 나타낸다. 그렇지 않은 경우엔 세그먼트를 포함하지 않도록 오디오를 자른다. 마지막으로 <<|endoftranscript|>토큰을 추가한다. 이전 컨텍스트 텍스트에 대해서만 훈련 손실을 가려내고, 모든 다른 토큰을 예측하도록 모델을 훈련한다.
2.4 Training Details
Whisper의 스케일링 특성을 연구하기 위해 다양한 크기의 모델을 훈련한다.

FP16, 동적 손실 스케일링, 그리고 activation checkpointing을 사용하여 가속기 간에 데이터 병렬 처리로 훈련한다. 모델은 AdamW와 gradient norm clipping을 사용하여 훈련되었으며, 첫 2048개 업데이트 동안의 warmup 이후에 선형 학습률 감소로 학습률을 0까지 감소시켰다. 256개의 세그먼트 배치 크기를 사용하고, 모델은 데이터셋을 두번에서 세번종도 훑는 2^20개 업데이트 동안 훈련된다. 몇개의 에포크만 훈련하기 때문에 과적합은 크게 문제가 되지 않고, 데이터 증강이나 정규화를 사용하지 않고, 대신 이러한 대규모 데이터셋에 포함된 다양성을 활용하여 일반화와 견고성을 장려한다.
3. Experiments
3.1 Zero-shot Evaluation
Whisper의 목표는 데이터셋 특정 파인튜닝 없이도 특정 분포에서 높은 품질의 결과를 신뢰성있게 제공하는, 단일하고 견고한 음성 처리 시스템을 개발하는 것이다. 이를 위해 다양한 도메인, 작업 및 언어 간에 잘 일반화되는지 여부를 확인하기 위해 다양한 음성처리 데이터셋을 재사용한다. 이러한 데이터셋에 대해 훈련 및 테스트 분할이 포함된 표준 평가 프로토콜을 사용하는 대신, 저자는 각 데이터셋에 대해 훈련 데이터를 사용하지 않고 제로샷 설정에서 whisper을 평가하여 넒은 범위의 일반화를 측정한다.
3.2 Evaluation Metrics
음성 인식 연구에서는 일반적으로 단어 오류율(WER=Word Error Rate)지표를 기반으로 시스템을 평가하고 비교한다. 그러나 WER은 문자열 편집 거리에 기반하므로 모델의 출력과 참조 전사 간의 모든 차이를 패널티를 준다. 이는 전사 스타일의 사소한 차이를 포함하여 인간에 의해 올바르게 판단될 수 있는 모든 차이에 패널티를 준다. 결과적으로 인간에 의해 정확하다고 판단될 수있는 전사를 출력하는 시스템도 형식의 적은 차이로도 큰 WER를 가질 수 있다. 이는 모든 전사 작업에 문제가 될 수 있지만, 특히 Whisper와 같은 모델의 경우에는 특정 데이터셋 전사 형식의 예시를 관찰하지 않기 때문에 문제가 심각해진다.
인간의 판단과 더 잘 관련된 평가 지표를 개발하는 것은 현재 활발하게 연구되고 있지만 음성인식에서 널리 채택되지는 않았다. 저자는 WER 계산 이전에 텍스트를 철저히 표준화하여 의미없는 차이의 패널티를 최소화함으로써 이 문제를 해결하기로 결정했다. 텍스트 정규화기는 WER이 Whisper 모델을 무해한 차이로 처벌하는 일반적인 패턴을 식별하기 위해 반복적인 수동 검토를 통해 개발되었다. (부록 C참조) 일부 데이터셋에서는 데이터셋의 참조 전사가 축약어와 공백으로 단어를 구분하는 등 이상한 동작으로 WER이 50%까지 감소. 이는 Whisper 모델의 전사 스타일에 과적합 될 위험이 있음. 저자는 텍스트 정규화기의 코드를 공개해서 쉬운 비교와 분포 범위 밖에서의 음성 인식 시스템 성능 연구를 돕고자 함.
3.3 English Speech Recognition
2015년에 발표된 Deep Speech 2에서는 LibriSpeech의 test-clean 세트를 전사할 때 인간 수준의 성능을 달성한 음성 인식 시스템을 보고했다. 그 당시에는 음성에서 더 개선될 여지가 없다고 결론을 내렸으나, 7년이 지난 현재에는 그들의 SOTA-WER은 5.3%에서 1.4%로 추가적으로 73%나 떨어졌다. 이는 인간수준의 오류율 5.8%보다 훨씬 아래이다. 그럼에도 불구하고 LibriSpeech에서 훈련된 음성 인식 모델은 다른 환경에서 인간의 오류율보다 훨씬 높은 오류율을 보인다. 이런 훈련 데이터에 대한 "초인간적"performance와 "비인간적"performance 간의 격차를 설명하는 요인은 무엇인가?
저자는 인간과 기계의 동작 사이의 이 차이가 테스트 세트에서 인간과 기계의 성능을 측정하는 데 영향을 주는 다른능력들을 혼동하는데 기인한다고 의심했다.(뭔소리임?) 인간과 기예가 같은 테스트를 수행하는 경우에 어떻게 다른 기술이 테스트되는 것인가? 이 차이는 테스트 자체가 아닌 훈련방법에서 발생한다. 인간은 종종 특정 데이터 분포에 대해 비지도적으로 과제를 수행하도록 요청받는다. 따라서 인간의 성능은 분포 범위 밖의 일반화의 척도로 볼 수 있다. 하지만 기계 학습 모델은 일반적으로 평가 분포에서 많은 지도로 훈련을 마친 후에 평가되므로 기계 성능은 분포 범위 내의 일반화의 척도이다. 인간과 기계는 동일한 테스트 데이터를 기반으로 평가되지만, 훈련 데이터의 차이로 인해 두 가지 매우 다른 능력이 측정된다.
Whisper 모델은 다양하고 포괄적인 오디오 데이터 분포에서 훈련되고 zero-shot 설정에서 평가되기 때문에, 기존의 시스템보다 인간의 동작과 더욱 잘 일치할 수 있다. 이것이 사실인지를 확인하기 위해 Whisper 모델을 인간의 성능과 표준적으로 파인튜닝된 기계 학습 모델과 비교하여 어느 쪽과 더 일치하는 지 확인할 수 있다.

이 차이를 정량화 하기 위해 저자는 많은 분포/데이터셋에 걸친 평균 성능인 전반적인 강인성과 유효 강인성(effective robustness)을 검토한다. 유효 강인성은 일반적으로 in-distribution인 참조 데이터셋과 하나 이상의 out-of-distribution 데이터셋 사이의 예상 성능을 측정한다. 유효 강인성이 높은 모델은 참조 데이터셋에서의 성능을 기준으로 out-of-distribution 데이터셋에서 예상보다 우수한 성능을 나타내며, 모든 데이터셋에서 동일한 성능을 가질 수 있는 이상적인 상태에 가까워진다. 분석을 위해 본 논문에서는 현대 음성 인식 연구에서 중요한 역할을 하는 LibriSpeech를 참조 데이터셋으로 사용하며, 이 데이터셋에 기반한 다양한 모델들의 이용 가능성으로 인해 강인성 특성을 성격화할 수 있다. 저자는 12개의 다른 학술적 음성 인식 데이터셋을 사용하여 out-of-distribution 행동을 연구한다. (자세한 내용은 부록 A)

주요 결론은 그림 2와 표 2에 요약되어 있다. 최고의 Zero-shot Whisper 모델은 상대적으로 보통 수준의 LibriSpeech clean-test WER인 2.5를 보이며, 이는 현대의 지도학습 기준선이나 2019년 중반의 최첨단 기술 수준과 비슷하다. 그러나 zero-shot Whisper 모델은 지도 학습된 LibriSpeech 모델과는 다르게 매우 다른 강인성 특성을 가지며, 다른 데이터셋에서 모든 벤치마크된 LibriSpeech 모델을 큰폭으로 앞서나간다. 심지어 가장 작은 zero shot whisper 모델도 다른 데이터셋에서 비교했을 때 libriSpeech 모델과 거의 경쟁수준이다. 그림 2에서 인간과 비교했을 때, 최고의 zero-shot Whisper 모델은 정확성과 강인성 면에서 인간과 거의 일치한다. Zero-shot Whisper 모델은 다른 음성 인식 데이터셋에서 평균 상대 오류 감소율인 55.2%를 달성했다.
이 결과는 기계 학습 시스템의 능력을 과대평가하는 오해를 피하기 위해, 특히 인간의 성능과 비교할 때, 모델의 zero shot 및 out of distribution 평가에 더 중점을 두어야 함을 시사한다.
3.4 Multi-lingual Speech Recognition

표 3에서 이전 연구들과의 비교를 위해 두가지 low-data 벤치마크인 Multilingual LibriSpeech(MLS)와 VoxPopuli의 결과를 보여준다.
Whisper 모델은 Multilingual LibriSpeech(MLS)에서 우수한 성능을 발휘하여 XLS-R, mSLAM, 그리고 Maestro를 제로 샷 설정에서 능가한다. 다만 이 결과를 위해 간단한 텍스트 표준화 기법을 사용했으며, 이로 인해 직접적인 비교나 SOTA 성능 주장은 할 수 없다. (=의미있는 결과는 아닌듯) 그러나 VoxPopuli에서는 Whisper가 이전 연구들보다 상당히 성능이 떨어지며, 원 논문의 VP-10K 기준 모델만을 앞질렀다. Whisper모델이 VoxPopuli에서 성능이 저하되는 이유로는 다른 모델들이 이 데이터셋을 비지도 사전학습 데이터의 주요 원천으로 사용하고 있으며, 데이터셋 자체가 상당량의 지도 학습 데이터를 가지고 있어 파인 튜닝에 유리한 영향을 미칠 수 있다고 추측한다. MLS는 각 언어당 10시간의 학습 데이터를 가지고 있지만, VoxPopuli의 경우 언어당 평균 학습 데이터 양이 대략 10배 더 많다.
이 두 가지 벤치마크는 다소 한정적인데, 이는 15개의 고유한 언어만을 포함하고 있으며 대부분의 언어가 Indo-European 언어 패밀리에 속하며 많은 언어가 high-resource language에 속하기 때문이다. 이러한 벤치마크는 Whisper 모델의 다중 언어 능력을 연구하기에 제한적인 커버리지와 공간을 제공한다. Whisper 모델은 75개의 언어의 음성 인식을 위한 훈련 데이터를 포함하고 있다. Whisper의 성능을 보다 폭넓게 연구하기 위해서 Fleurs 데이터셋의 성능도 보고한다. 특히 저자는 주어진 언어에 대한 훈련 데이터 양과 해당 언어의 결과적인 제로샷 성능 사이의 관계를 연구하는데 중점을 두었다. 이 관계를 그림 3에서 시각화하였다. 저자는 단어 오류율의 로그와 언어당 훈련 데이터 양의 로그 간의 강한 제곱 상관 계수인 0.83을 발견했다. 이 로그-로그 값에 대한 선형 피팅의 회귀 계수를 확인하면, 훈련 데이터의 16배 증가마다 WER이 절반으로 줄어든다는 추정치를 얻을 수 있다. 또한 이 추세에 따라 예상보다 성능이 나쁜 큰 이상치들 중 많은 언어들은 특이한 스크립트를 가지며 인도-유럽 언어로 이루어진 대부분의 훈련 데이터셋과 더 관련이 없는 언어들이다. 예를들어 히브리어, 텔루구어, 중국어 및 한국어 등이다. 이러한 차이는 언어 간의 언어적 거리로 인한 전이의 부족, 바이트 수준 BPE 토커나이저가 이러한 언어들과 잘 맞지않음, 데이터 품질의 차이 등을 요인으로 들 수 있다.

3.5 Translation
Whisper모델의 번역 능력을 연구하기 위해 CoVoST2의 X→EN 하위 세트에서의 성능을 측정한다. 저자는 Maestor, mSLAM, XLS-R과의 성능을 비교한다. 저자는 CoVoST2의 훈련 데이터를 사용하지 않고도 29.1BLEU의 제로샷 성능으로 새로운 최고 성과를 달성했다. 이는 사전훈련 데이터셋에 포함된 68,000시간의 X→EN 번역 데이터에 기인하는데, 이 데이터는 노이즈가 있지만 CoVoST2의 X→EN 번역을 위한 861시간의 훈련 데이터보다 훨씬 크다. Whisper 평가는 제로샷 방식이므로, CoVoST2의 가장 적은 리소스를 가진 그룹에서 특히 우수한 성능을 보이며, mSLAM 대비 6.7 BLEU 개선이 있다. 그러나 최고의 Whisper 모델은 실제로는 최고 리소스 언어에 대해 Maestro와 mSLAM을 평균적으로 개선하지 않는다.

더 다양한 언어를 포함한 추가 분석을 위해 Fleurs 데이터셋을 음성인식 데이터셋에서 번역 데이터셋으로 활용한다. 동일한 문장이 각 언어별로 전사되기 때문에 영어 전사본을 참조 번역으로 사용한다. 그림 4에서는 언어별 번역 훈련 데이터양과 Fleurs에서의 제로샷 BLEU 점수 간의 상관 관계를 시각화한다. 훈련 데이터 양이 증가함에 따라 개선되는 명확한 추세가 있지만, 이에 대한 제곱 상관 계수는 음성인식의 0.83보다 훨씬 낮은 0.24이다. 이는 오디오 언어 식별의 오류로 인해 훈련 데이터가 더 노이즈가 있는 것이 일부 원인일 것으로 의심된다. 예를 들어, 웨일스어는 9,000시간의 번역 데이터가 있는 것으로 알려져 있음에도 불구하고 13 BLEU로 예상보다 훨씬 성능이 나쁜 outlier이다. 이 큰 웨일스어 번역 데이터양은 번역 데이터 전체에서 4위에 위치하며, 프랑스어, 스페인어, 러시아어와 같은 가장 많이 사용되는 언어들보다 앞선다. 조사 결과, 대부분의 웨일스어 번역 데이터는 실제로 영어 오디오와 영어 자막으로 구성되어 있으며, 이 영어 오디오가 언어 식별 시스템에 의해 잘못된 웨일스어로 분류되어 번역 훈련 데이터로 포함되었다는 것을 데이터셋 생성 규칙에 따라 확인할 수 있다.
3.6 Language Identification
언어 식별을 평가하기 위해 Fleurs 데이터셋을 사용한다. Whisper의 제로샷 성능은 이곳에서 이전의 지도 학습 기반 연구에 비해 경쟁력이 없으며, 지도 학습 기준에서 13.6% 성능 저하를 보인다. 그러나 Whisper는 Fleurs에서 언어 식별 작업에 큰 불리함을 겪는다. 왜냐하면 Whisper 데이터셋에는 Fleurs의 102개 언어 중 20개의 언어에 대한 훈련 데이터가 없기 때문에 정확도는 최대 80.4%로 상한이 된다. 82개의 공통 언어에서는 최고의 Whisper 모델이 80.3% 의 정확도를 달성한다.
3.7 Robustness to Additive Noise
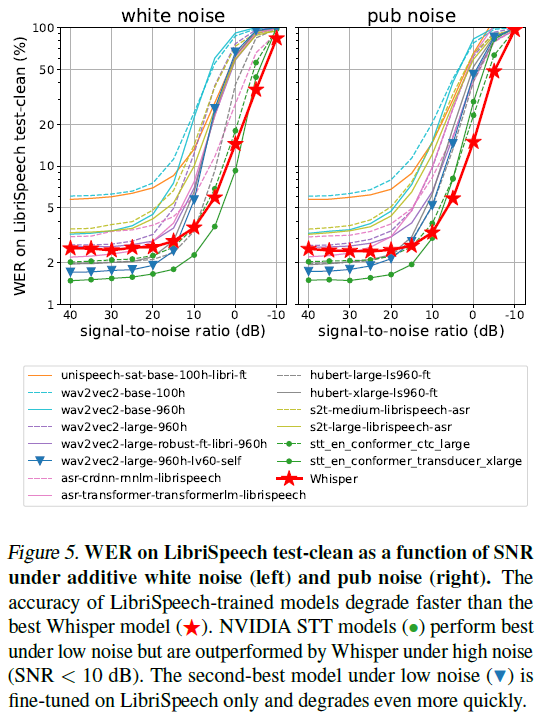
저자는 Whisper 모델과 14개의 LibriSpeech로 훈련된 모델들의 노이즈 강인성을 테스트하기 위해 오디오에 흰색 잡음이나 Audio Degradation Toolbox에서 제공하는 펍 잡음을 추가했을 때의 단어 오류율(WER)을 측정했다. 펍 잡음은 혼잡한 식당이나 펍과 같은 환경에서 주변 소음과 애매하게 들리는 수다를 나타내는 자연스러운 잡음. 14개의 모델 중 12개는 LibriSpeech에서 사전 훈련 또는 파인튜닝된 모델이며, 나머지 2개는 SpeechStew와 같은 이전 연구와 유사한 혼합 데이터셋에서 훈련된 NVIDIA STT 모델이다. 주어진 신호 대 잡음비(SNR)에 해당하는 첨가 잡음의 수준은 개별 예제의 신호 파워를 기반으로 계산된다. 그림 5는 첨가 잡음이 더 강해질수록 ASR 성능이 저하되는 모습을 보여준다. 저잡음(40dB SNR)에서는 본 논문의 제로샷 성능보다 우수한 성능을 보이는 모델들이 많이 있다. 이는 그 모델들이 주로 LibriSpeech에서 훈련되었기 때문에 예상된 결과이다. 그러나 모든 모델들은 잡음이 더 강해지면서 빠르게 성능이 저하되고, SNR이 10dB 이하인 펍 잡음 하에서는 Whisper 모델보다 성능이 더 나쁘다. 이는 Whisper 모델의 잡음에 대한 강인성을 보여주고, 특히 펍 잡음과 같은 자연스러운 분포 변화에서 더욱 강력하게 작동한다는 것을 나타낸다.
3.8 Long-form Transcription
Whisper 모델은 30초 오디오 청크로 훈련되며, 한번에 더 긴 오디오 입력을 처리할 수 없다. 이는 대부분의 짧은 발화로 구성된 학술 데이터셋에서는 문제가 되지 않지만, 실제 응용 프로그램에서는 몇 분 또는 몇 시간에 이르는 오디오를 전사해야 하는 시도를 해야한다. 저자는 모델이 예측한 타임스탬프에 따라 30초 단위의 오디오 세그먼트를 연속적으로 전사하고 창을 이동시킴으로써 긴 오디오의 버퍼 전사를 수행하는 전략을 개발했다. 긴 오디오를 신뢰성있게 전사하기 위해 반복성과 모델 예측의 로그 확률을 기반한 빔 서치와 temperature scheduling이 중요하다는 것을 관찰하였다. (자세한건 섹션 4.5에)
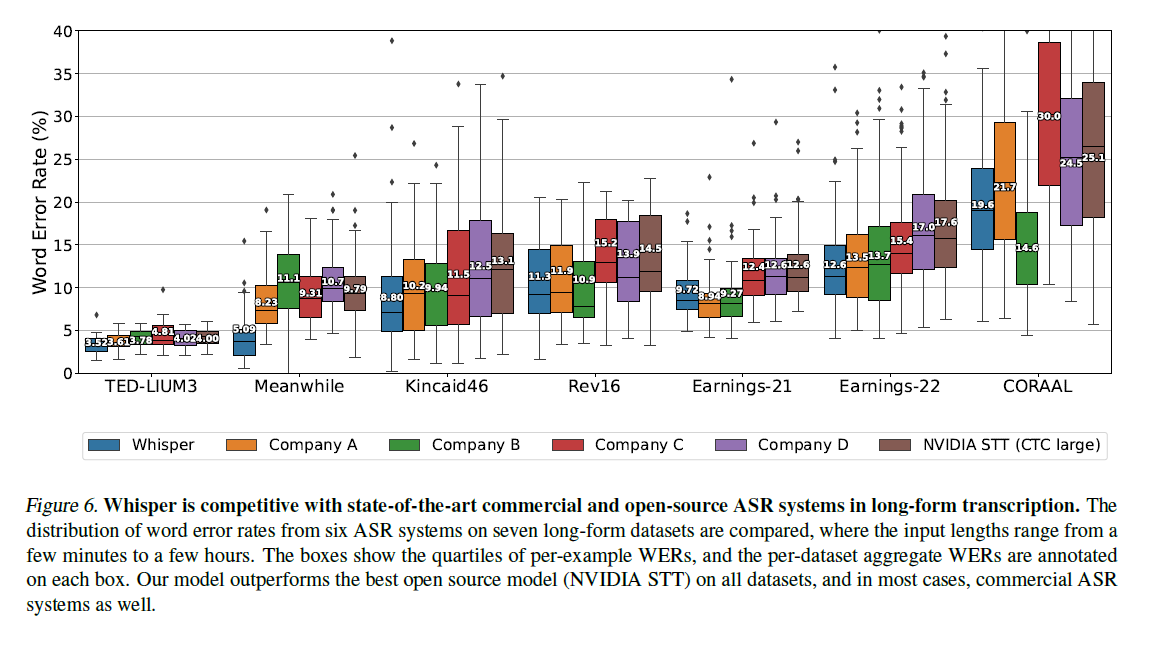
저자는 다양한 길이와 녹음 조건을 가진 음성 녹음으로 구성된 일곱 가지 데이터셋의 장형 전사(Long-form Transcription) 성능을 평가한다. 이에는 TED-LIUM3의 장형 적응 버전(각 예시가 전체 TED 대화인)과 The Late Show with Stephen Colbert에서 가져온 전문 용어가 포함된 세그먼트(Meanwhile), 온라인 블로그에서 ASR 벤치마크로 사용된 동영상/팟캐스트 세트(Rev16 및 Kincaid46), 수익 발표 회의 녹음(Del Rio 등) 및 Corpus of Regional African American Language (CORAAL)에서 가져온 전체 인터뷰(Gunter 등)등이 있다. (장형 데이터셋에 대한 내용은 부록 A)
본 논문에서는 오픈소스 모델과 상용 ASR 서비스 4개와의 성능을 비교한다. 결과는 그림 6에 요약되어 있음. Whisper와 4개의 상용 ASR서비스의 단어 오류율 분포와 NeMo 툴킷에서 성능이 가장 우수한 NVIDIA STT Conformer-CTC Large 모델의 결과를 보여준다. 모든 상용 ASR 서비스는 2022년 9월 1일 기준으로 기본 영어 전사 설정을 사용하여 쿼리되었으며, NVIDIA STT 모델은 장형 전사를 가능하게 하기 위해 FrameBatchASR 클래스의 버퍼드 추론 구현을 사용했다. 결과는 Whisper가 대부분의 데이터셋에서 비교 모델보다 더 좋은 성능을 보인다는 것을 보여준다. 특히 Meanwhile 데이터셋은 흔하지 않은 단어들로 구성되어 있다. 또한, 일부 상용 ASR 시스템이 이러한 공개 데이터셋 중 일부로 훈련되었을 가능성이 있으며, 따라서 이러한 결과는 시스템의 상대적인 강건성을 정확하게 반영하지 못할 수도 있다는 점에 주의해야 한다.
3.9 Comparison with Human Performance
각 데이터셋마다 애매하거나 분명하지 않은 음성 및 레이블링 오류로 인해, 각 데이터셋마다 불가피한 오류수준이 다르며, ASR 시스템의 WER 지표만으로는 각 데이터셋에서의 개선 여지를 파악하기 어렵다. Whisper의 성능이 인간의 성능에 얼마나 가까운지를 정량화하기 위해 Kincaid46 데이터셋에서 25개의 녹음을 선택하고, 5개의 서비스를 사용하여 전문 텍스트 변환 작업자가 작성한 전사를 얻었다. 이중 하나는 컴퓨터 지원 전사를 제공하며, 다른 네 가지는 완전히 인간이 수행한 전사이다. 오디오 선택은 스크립트와 스크립트 없는 방송, 전화 및 VolP 통화, 회의 등과 같은 다양한 녹음 조건을 포함한다. 그림 7은 25개의 녹음의 개별 WER및 집계 WER를 가지며, 순전히 인간에 의한 성능은 Whisper보다 약간 더 낮다. 이 결과는 Whisper의 영어 ASR 성능이 완벽하지는 않지만 인간 수준의 정확도에 매우 가깝다는 것을 나타낸다.

4. Analysis and Ablations
4.1 Model Scaling
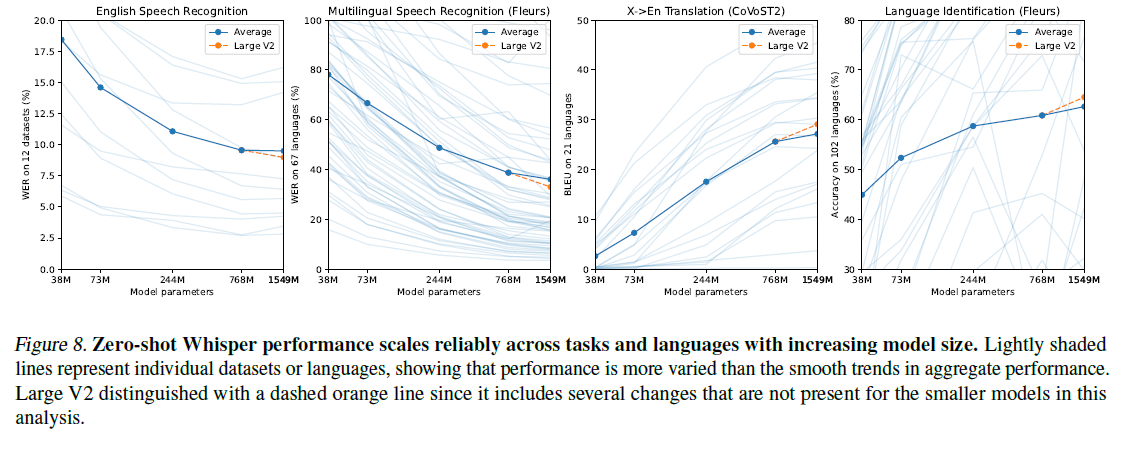
약하게 지도된 학습 접근법의 가장 큰 장점 중 하나는 기존 지도학습보다 훨씬 큰 데이터셋을 활용할 수 있다는 것이다. 그러나 이는 gold-standard 지도보다 훨씬 더 노이즈가 많고 품질이 낮은 데이터를 사용하는 대가로 오게된다. 이 접근법은 처음에는 유망해 보일지라도 이러한 종류의 데이터로 훈련된 모델의 성능이 데이터셋의 내재 품질 수준에 포화될 수 있으며, 이는 인간 수준보다 훨씬낮을 수 있다는 단점이 있다. 관련 단점은 데이터셋에 대한 용량과 계산 능력이 증가함에 따라 모델이 데이터셋의 독특한 특성을 활용하는 것을 배울 수 있으며, 심지어 일반화 능력이 저하되어 데이터 분포 외부의 데이터에 대한 강건한 일반화 능력이 감소할 수도 있다는 것이다.
이러한 경우를 확인하기 위해, 모델 크기의 함수로 Whisper 모데르이 제로샷 일반화를 연구한다. 분석 결과는 그림 8에 요약되어 있다. 영어 음성 인식을 제외하고는, 다국어 음성 인식, 음성 번역 및 언어 식별을 포함한 영역에서 모델 크기가 증가함에 따라 성능이 계속해서 향상되었다. 영어 음성 인식에서의 성능 저하는 인간 수준의 성능에 접근함에 따라 포화 효과를 인한 것일 수 있다.(섹션 3.9에 분석되어있음)
4.2 Dataset Scaling
Whisper 데이터셋은 68,000시간에 이르는 레이블이 달린 오디오로 구성되어 있어서, 이는 지도 학습 기반 음성 인식에서 생성된 가장 큰 데이터셋 중 하나이다. Whisper의 성능에 있어서 원시 데이터셋의 크기가 얼마나 중요한지 알아보기 위해, 데이터셋의 하위 샘플(subsample) 버전에서 중간 규모의 모델들을 훈련시켰다. 이 하위 샘플은 전체 데이터셋 크기의 0.5%, 1%, 2%, 4%, 8%에 해당한다. 동일한 중간 규모의 모델을 전체 데이터셋에 대해 훈련한 모델과 비교하여 성능을 평가했다. 각 데이터셋 크기에 대해 검증 손실에 기반한 조기 종료를 사용하여 모델의 체크포인트를 선택했다. 평가는 지수 이동 평균 추정 파라미터(exponetial moving average estimage of the parameters)를 사용하여 수행되었으며, 하위 샘플 데이터셋에서 조기 종료로 인해 학습률이 완전히 0으로 감소하지 않는 영향을 줄이기 위해 0.9999의 평활화 비율을 사용했다. 영어 및 다국어 음성 인식 그리고 X→EN 번역의 성능은 표 6에 보고되었다.

모든 작업에서 데이터셋의 크기의 증가는 성능 향상으로 이어진다. 그러나 작업과 크기에 따라 향상 속도에 상당한 변동성을 관찰한다. 영어 음성 인식에서는 3,000시간부터 13,000시간까지 빠르게 개선되며, 13,000시간부터 54,000시간까지 개선 속도가 둔화된다. 전체 데이터셋을 사용하는 것은 크기를 추가로 12.5배로 늘리는 것으로, WER에서 1포인트만 더 감소시킨다. 이는 영어 음성 인식의 모델 크기 확장과 관련하여 관찰된 효과와 유사하며, 인간 수준의 성능에 접근할 때 포화 효과로 설명될 수 있다.
다양한 언어의 음성 인식에서는 WER 개선이 54,000시간까지 거의 거듭 제곱 법칙의 경향을 따르다가 이후에 이 경향에서 벗어나며, 전체 데이터셋 크기로 확장할 때 추가로 7포인트만 개선된다. X→EN 번역 작업에서는 7,000시간 이하의 오디오로 훈련할 경우 성능이 거의 제로이며, 54,000시간까지 대략적으로 로그 선형적인 개선 경향을 보이며, 전체 데이터셋 크기로 확장할 때도 향상 속도가 둔화되는 것을 확인할 수 있다.
54,000시간에서 680,000 시간의 전체 데이터셋 크기로 이동할 때 성능의 개선이 감소하는 경향은 현재의 최고의 Whisper 모델이 데이터셋 크기에 비해 미훈련 상태이며, 더 긴 훈련과 큰 모델의 조합으로 성능을 더 향상시킬 수 있다는 가능성을 시사한다. 또한 음성 인식의 데이터셋 크기에 따른 성능 향상의 한계에 점점 다가가고 있다는 것을 시사하기도 한다. 이러한 설명 사이에서 "스케일링 법칙(Scaling laws)"을 특성화하기 위해 추가적인 분석이 필요하다.
4.3 Multitask and Multilingual Transfer
다중 작업과 다중 언어로 단일 모델을 공동으로 훈련하는 것은 여러 작업의 학습 간 상호작용으로 인해 단일작업이나 언어만 훈련하는 것보다 성능이 저하될 수 있는 부정적인 전이의 가능성이 있다. 이러한 현상이 발생하는지 여부를 조사하기 위해, 저자는 표준적인 다중 작업 및 다중 언어 훈련 설정과 비교하여 영어 음성 인식만을 훈련한 모델의 성능을 측정하고, 영어 음성 인식 벤치마크에서 평균 성능을 측정했다. 영어 음성 인식 작업에 소요된 FLOPs의 양을 조정했는데, 공동 훈련 설정에서 이 작업에 사용되는 계산 자원은 전체 계산 자원의 65%만 사용되기 때문이다. 이렇게 함으로써 동일한 크기의 영어 전용 모델과 비교했을 때 작업의 미훈련으로 인한 혼란을 제거하였다.
결과는 그림 9에서 시각화되어있다. 작은 모델의 경우 중간 정도의 계산 자원을 사용하여 훈련한 경우 다중 작업 및 다중 언어 간에 부정적인 전이가 실제로 발생한다는 것을 보여준다. 동일한 계산 자원을 사용하여 훈련한 영어 전용 모델보다 공동 모델의 성능이 떨어진다. 그러나 다중 작업 및 다중 언어 모델은 더 큰 규모로 확장되며, 가장 큰 실험에서는 작업 당 사용된 계산 자원을 조정하지 않아도 공동 모델이 영어 전용 모델보다 약간 더 우수한 성능을 보낸다.

4.4 Text Normalization
Whisper와 함께 개발한 텍스트 정규화 기술은 단순한 단어 오류를 보정하기 위한 것. 전사의 일반적인 변동을 처리하는 대신에 Whisper의 특이성에 과적합될 위험이 있다. 이를 확인하기 위해 Whisper에서 사용하는 저자의 정규화기와 FairSpeech 프로젝트에서 독립적으로 개발한 정규화기의 성능을 비교하였다. 그림 10에서 차이를 볼 수 있음. 대부분의 데이터셋에서 두 정규화기는 유사한 성능을 보여주며, Whisper와 비교된 오픈 소스모델의 WER 감소에 중요한 차이가 없다. 그러나 일부 데이터셋인 WSJ, CallHome 및 Switchboard에서는 저자의 정규화기가 Whisper 모델의 WER을 더 크게 감소시킨다. 이러한 차이는 Ground truth의 형식과 두 정규화기가 어떻게 패널티를 주는지에 기인할 수 있다. 예를들어 저자의 정규화기는 "You're"대"you are"와 같은 일반적인 영어 축약형의 차이를 패널티를 주지 않았으며, WSJ에서는 숫자 및 통화 표현의 서면 형식과 발화 형식을 표준화했다. (EX : "sisty-dight million dollars", "$68 million").
4.5 Strategies for Reliable Long-form Transcription
Whisper를 사용하여 장문 오디오를 전사하는 경우, 타임 스탬프 토큰의 정확한 예측은 모델의 30초 오디오 컨텍스트 창을 이동시킬 양을 결정하는 데 중요하다. 하나의 창에서 부정확한 전사는 이후 창의 전사에 부정적인 영향을 미칠 수 있다. 이러한 실패 사례를 피하기 위해 저자는 장문 전사의 결과에 적용되는 일련의 휴리스틱을 개발했다. (3.8, 3.9절에서 나온 결과에 적용됨) 첫째, 본 논문에서는 로그 확률을 점수 함수로 사용하여 5개의 빔을 사용하는 빔 서치를 사용하여 우선 순위 반복을 줄인다. Greedy 디코딩에서 반복 루프가 더 자주 발생하기 때문. 온도 0에서 시작하여 생성된 토큰의 평균 로그 확률이 -1보다 낮거나 생성된 텍스트의 gzip 압축률이 2.4보다 높은 경우에만 온도를 0.2씩 증가시키는 방식으로 온도를 증가시킨다. 이전 텍스트를 이전 텍스트 조건으로 사용할 때 적용된 온도가 0.5 미만인 경우 성능이 더욱 향상된다. 저자는 <|nospeech|> 토큰 자체 만으로는 음성이 없는 세그먼트를 구별하는 데 충분하지 않다는 것을 발견했지만, 음성 활동 감지를 더 신뢰할 수 있게 만들기 위해 음성이 없는 확률 임계값 0.6과 평균 로그 확률 임계값 -1을 결합한다. 마지막으로 모델이 입력의 처음 몇 단어를 무시하는 오류 모드를 피하기 위해 초기 타임스탬프 토큰을 0.0과 1.0초 사이로 제한한다. 표 7은 위의 각 개입을 점진적으로 추가하면 전반적으로 WER이 감소하지만, 데이터셋 전체에 균일하게 감소하지 않는다는 것을 보여준다. 이러한 휴리스틱은 노이즈 있는 예측을 우회하는데 사용된다. 장문 디코딩의 신뢰성을 더욱 향상시키기 위해서는 더 많은 연구가 필요하다.
5. Related Work
Scaling Speech Recognition
음성인식 연구에서 일관된 주제는 컴퓨팅, 모델 및 데이터셋의 확장의 이점을 문서화하는것이었다. 초기의 음성인식 모델 적용 연구는 모델의 깊이와 크기가 향상된 성능을 보였고, GPU 가속화를 활용하여 더 큰 모델을 학습하기 쉽게 만들었다. 추가적인 연구에서는 데이터셋의 크기가 커질수록 딥러닝 기반 음성인식 방법의 이점이 커졌으며, TIMIT 학습 데이터로 단지 3시간을 사용할때는 이전의 GMM-HMM 시스템과 경쟁할 수 있었지만, 2,000시간의 스위치보드 데이터셋으로 훈련시킬 때는 단어 오류율을 30% 감소시킬 수 있었따. Liao등 약하게 지도된 학습을 활용하여 딥러닝 기반 음성인식 데이터셋을 1,000시간 이상 확장하는 초기 사례이다. 이러한 경향은 Deep Speech2로 이어졌으며, 이는 16개의 GPU에서 고처리량 분산 학습을 개발하고 12,000 시간의 학습 데이터로 확장함과 동시에 그 규모에서 지속적인 발전을 보여준다. Narayanan 등은 반지도 학습 사전 훈련을 활용하여 데이터셋의 크기를 훨씬 더 확장시킬 수 있었으며, 162,000시간의 레이블 된 오디오에 대한 학습을 연구할 수 있다. 더 최근의 연구에서는 10억개의 파라미터 모델과 최대 1,000,000시간의 학습 데이터 사용에 대해 탐구하였다.
Multitask Learning
멀티태스크 학습은 오랫동안 연구되어온 분야. 음성 인식에서는 멀티언어 모델이 10년정도 연구됨. NLP에서 멀팉스크 학습을 탐구한 기반적인 작업은 2011년. Seq2Seq 프레임워크에서 멀티태스크 학습을 위해 여러 인코더와 디코더를 사용한 연구는 2015. 2017년에는 Johnson등에 의해 처음으로 언어 코드를 사용하여 공유 인코더/디코더 아키텍처를 기계 번역에 적용하여 별도의 인코더와 디코더가 필요하지 않게 됨. 이 접근법은 2019년 이후 Text2Text로 간소화되었으며 이후 대형 트랜스포머 언어 모델의 성공을 통해 널리 알려지게 되었다. 2020년에는 최신 딥러닝 음성 인식 시스템을 여러 언어로 하나의 모델에서 공동으로 학습하는 것을 시연하고, 이러한 연구를 50개의 언어에 대한 10억개의 파라미터 모델로 확장하였다. MUTE와 mSLAM은 텍스트 및 음성 언어 작업에 대해 공동으로 학습을 수행하여 상호 전이를 보여주었다.
Robustness
모델의 전이 효과성과 분포 이동 및 기타 변동에 대한 강건성은 기계학습의 많은 분야에서 오랫동안 연구되어왔으며 현재도 활발히 연구되고 있다. 2011년에 기계 학습 모델이 데이터셋 간에 일반화를 제대로 수행하지 못하는 문제가 이미 강조되었다. 다른 많은 연구들도 마찬가지로 IID 테스트 세트에서 높은 성능을 보이더라도 약간의 다른 설정에서 모델이 여전히 많은 오류를 나타낸다. 최근에는 이미지 분류의 강건성과 질의 응답 모델의 강건성도 조사된다. 중요한 발견은 다양한 도메인에서의 학습이 강건성과 일반화를 증가시킨다는 것이다. 이러한 결과는 음성 인식을 포함한 NLP및 컴퓨터 비전을 포함한 다양한 분야에서 복제되었다.
6. Limitations and Future Work
Improved decoding strategies
Whisper를 확장함에 따라, 저자는 대규모 모델이 비슷한 소리를 내는 단어를 혼동하는 등 지각 관련 오류를 점진적이고 신뢰할 수 있는 방식으로 줄이는 것을 관찰하였다. 그러나 여전히 남아있는 오류 중에서, 특히 장문의 전사에서 더욱 강한 오류를 보이며, 분명히 인간/지각과는 관련이 없는 것들이 있다. 이러한 오류는 Seq2Seq 모델, 언어모델, Text-Audio 정렬의 실패 모드의 조합으로 나타난다. 이는 반복 루프에 갇히는 문제, 오디오 세그먼트의 처음이나 마지막 몇개의 단어를 전사하지 않는 문제, 또는 완전히 허구적인 현상으로, 모델이 실제 오디오와 전혀 관련없는 전사를 출력하는 문제를 포함한다. 4.5절에서 논의한 디코딩 세부 사항이 크게 도움되지만, 저자는 고품질의 지도 학습 데이터로 Whisper 모델을 세밀하게 튜닝하거나 강화학습을 사용하여 디코딩 성능에 더 직접적으로 최적화 하는 것이 오류를 줄일 수 있는지의 여부는 모른다고 함.
Increase Training Data For Lower-Resource Language
그림 3에 따르면 Whisper의 음성 인식 성능은 여러 언어에서 여전히 매우 낮다. 동일한 분석은 언어의 훈련 데이터 양에 따라 언어의 성능이 매우 잘 예측된다는 명확한 개선 경로를 제시한다. 이 논문의 사전 훈련 데이터셋은 데이터 수집 파이프라인의 편향으로 인해 매우 영어 중심적이며, 인터넷의 주로 영어 중심적인 부분에서 데이터를 수집하였다. 대부분의 언어는 1000시간 미만의 훈련 데이터만을 가지고 있다. 이러한 희귀 언어들의 데이터양을 증가시키기 위한 효과적인 노력은 전체적인 훈련 데이터셋의 크기를 크게 증가시키지 않아도 평균 음성 인식 성능을 크게 개선할 수 있을 것이라고 저자는 주장.
Studying fine-tuning
본 연구에서는 음성 처리 시스템의 견고성 특성에 초점을 맞추어 Whisper의 제로샷 전이 성능만을 연구하였다. 이는 일반적인 신뢰성을 대표하는 중요한 조건이기 때문에 중요한 설정이지만, 고품질의 지도 음성 데이터가 존재하는 많은 도메인에서는 성능을 더 개선하기 위해 파인튜닝이 가능할 것으로 예상된다고 한다. 파인튜닝을 연구하는 추가적인 이점은 훨씬 더 일반적인 평가 설정이기 때문에 이전 연구와 직접적인 비교가 가능하다는 점이다.
Studying the impact of Language Models on Robustness
서론에서 주장한 것처럼저자는 Whisper의 견고성이 오디오 조건부 언어 모델인 강력한 디코더에서 일부 기인한다고 추측한다. 현재까지는 Whisper의 이점이 인코더, 디코더, 혹은 둘다를 훈련시킨 값인지가 명확하지 않음. 이를 위해서 Whisper의 다양한 설계 요소를 제거하는 등의 연구가 필요.
Adding Auxiliary
Whisper는 비지도 사전 훈련 또는 self-teaching 방법이 없어서 최근의 최첨단 음성 인식 시스템과는 확연히 달라진다. 이를 통합하면 더욱 좋은 결과를 얻을 수도 있음.
7. Conclusion
Whisper은 약하게 지도된 사전 훈련의 확장이 음성 인식 연구에서 현재까지 충분히 인식되지 않았음을 시사한다. 본 논문은 최근 대규모 음성 인식 작업에서 주로 사용된 자가지도 및 자가훈련 기법 없이 결과를 달성하며, 크고 다양한 지도된 데이터셋으로 훈련하고 제로샷 전이에 중점을 두는 것 만으로도 음성 인식 시스템의 견고성을 크게 개선할 수 있음을 보여준다.
이 페이퍼는 어느순간부터 아 괜히 전부 해석하네... 하는 생각을함
대부분의 논문의 경우 기술적인 세부 내용을 이해하는데 어렵기 때문에 쓸데없는 부분까지 모두 보는것이 도움이 될 수 있는데, 이 페이퍼는 세부 내용은 그림으로 떼우고 테스트 결과나 과정에 집중을 한다............
그래서 결국 이론적인 부분을 정확하게는 이해하지 못하겠음
Transformer나 음성 인식 시스템에 대한 바탕이 있어야 이해할 수 있을듯
아무리 그래도 그림1에 대한 설명이 이렇게까지 없는건 너무 불친절한 페이퍼이라고 생각한다
어쩐지 기술 관련 글이나 영상은 많이 없고 실행 관련만 잔뜩있더니....
그래도 음성인식 기술의 발전이 급성장하고 있다는 동향 파악에 만족



