이 논문은 개인적으로 읽을 일이 생겨서.. 읽기 시작햇는데
파파고에서 조금 어려운 말을 내 식으로 해석하고 내가 모르는 이론들을 추가로 더 조사한 정도다
대충 읽어서는 이해가 안돼서 진짜 한문단한문단 번역해서 쓸데없는 내용까지 있을수도.
중간중간 영어로 쓴 부분은 내가 공부하면서는 무슨느낌인지는 이해했지만 한글로 표현하기는 어려운.. 단순히 어휘력에 한계를 느껴 영어로 표시함
Abstract
Text-to-image 모델은 자연어를 통해서 이전에 없던 창조적인 자유를 제공한다. 그러나 이 자유가 어떻게 특정한 독특한 개념의 이미지를 생성하는지, 또는 새로운 역할과 장면에서 구성하는지는 불분명하다.
이 논문에서는 그런 창조적인 자유를 허가하는 심플한 접근법을 제공하는데, 객체 또는 스타일과 같이 사용자가 3~5장의 이미지만 넣으면 고정된 Text2img 모델의 임베딩 공간 안에서 새로운 "단어를" 통해 표현하는 방법이다.
특히 저자들은 단일 단어 임베딩이 독특하고 다양한 개념을 capture 하기에 충분하다는 증거를 발견했다.

(왼쪽 input) 특정 개념을 설명하는 사전 훈련된 T2I 모델의 임베딩 공간에서 새로운 Pseudo word (유사 단어)를 찾는다.
(오른쪽 output) 이러한 P word들은 새로운 문장으로 구성되어 새로운 scene에 대상을 배치하고 스타일 or 구성을 바꾸거나 새로운 제품으로 물들일 수 있다.
1. Introduction
최근 대규모 T2I 모델들은 굉장히 좋은 성능을 보여줬지만, 사용자가 text를 통해 원하는 대상을 어떻게 설명할 수 있는 지에 따라, 즉 사용자의 능력에 따라 사용이 제한된다.
대규모 모델에 새로운 개념을 추가하는 것은 보통 어려운 일이다. 각각의 새로운 개념에 대해 확장된 dataset로 모델을 재교육하게 되면 엄청난 비용이 요구되고, 또한 몇가지 예시에서 fine tuning 하는 것은 파괴적 망각으로 이어진다.
파괴적 망각 : 인공 신경망의 경우 single task에서는 뛰어난 성능을 보이는데, 다른 종류의 task를 학습하면 이전에 학습했던 task에 대한 성능이 현저하게 떨어지는 현상. 이는 이전 학습 dataset과 새로운 학습 dataset의 연관성과는 상관없이 정보를 대량으로 손실한다. >

sub-word segmentation : 우리가 사용하는 단어에는 이름, 신종어, 약어 등 단어장에는 존재하지 않는 것들이 섞여 있다. 이러한 Rare word problem에서 Out-of-vocabulary(OOV) 문제가 발생하고, 이를 막기 위한 것이 sub-word segmentation. 예를들어 "Transformer" => "Tr", "ans", "f", "ormer" 이런 식으로 분리한다. unknown word 처리에 효과적이고, 차원과 sparsiry 역시 줄일 수 잇다.
Out-of-vocabulary (OOV) : 자연어의 전처리 과정에서는 학습데이터의 모든 단어를 토큰화 하여 Vocabulary를 만들고 그 Vocabulary 를 기준으로 정수 인코딩(단어를 숫자로 표현함)을 하게된다. 새로운 단어 토큰이 들어왔을 때 vocabulary에 없을 경우 <UNK> unknown token을 반환한다.
이 논문에서는 사전 훈련된 T2I 모델의 text 임베딩 공간에서 새로운 단어를 찾아 이러한 문제 극복 방법을 제안한다.
(Figure 2) 텍스트 인코딩 프로세스의 첫번째 단계를 고려하면, 여기서 입력 문자열은 먼저 토큰 집합으로 변환되고, 그 후 각 토큰이 자체 임베딩 벡터로 대체된다. 이러한 벡터는 down stream 모델을 통해 공급된다. 이 논문의 목표는 새롭고 구체적인 개념을 나타내는 새로운 임베딩 벡터를 찾는 것이다.
저자들은 S*로 P word를 지정하고, 이를 통해 새로운 임베딩 벡터를 나타낸다. 이 P word는 다른 단어와 마찬가지로 취급되며 생성 모델에 대한 새로운 text queries를 구성하는데 사용될 수 있다.
중요한 것은 이 과정이 생성모델을 그대로 유지한다는 것이다. 그렇게 새로운 작업에 대한 비전과 언어 모델을 fine tuning할 때 일반적으로 손실되는 풍부한 텍스트 이해 및 일반화 기능(generalization capabilities)을 유지한다.
일반화(generalization) : 학습 데이터와 input data가 달라져도 출력에 대한 성능 차이가 나지 않도록 하는 것. 즉 모델의 Training data가 아니라 외부 data를 모델에 넣어도 Training data로 학습시켜서 얻은 것과 비슷한 값이 나오도록 하는 것.
이러한 P word를 찾기 위해 task를 inversion 중 하나로 프레임화 한다. 저자들은 고정된, 그리고 사전 훈련된 T2I 모델과 개념을 설명하는 3~5장의 적은 이미지 set를 받고, "A photo of S*" 형태의 문장이 적은 이미지 set에서 이미지를 재구성하여 단일 단어 임베딩을 찾는 것을 목표로 한다. 이 임베딩은 최적화 과정을 통해 발견되며, 이것이 바로 Textual inversion.
또한 저자들은 GAN inversion에 일반적으로 사용되는 도구를 기반으로 일련의 확장을 추가적으로 조사한다.
이러한 개념과 접근 방식의 효과를 입증하여
- 객체 주입
- 스타일 변환
- 포즈 변환
- 편향 줄이기
- 새로운 결과물 상상
을 보여 줄 수 있다.
2. Related work
1) Text-guided synthesis
Text-guided image synthesis (텍스트 유도 이미지 합성)은 GAN의 맥락에서 널리 연구되어 왔다. 일반적으로 conditional model은 attention 매커니즘 또는 cross modal 대조 접근법을 활용하여 주어진 쌍을 이룬 이미지 캡션 데이터셋의 샘플을 재현하도록 훈련된다. 최근에는 대규모 auto regressive 또는 diffusion model을 활용하여 인상적인 비주얼 결과들이 나왔다.
conditional model을 훈련하는 대신, 몇가지의 접근 방식은 테스트 시간 최적화를 사용하여 사전 훈련된 생성 모델의 latent space를 탐색한다. 이러한 모델들은 일반적으로 CLIP과 같은 보조 모델에서 파생된 T2I 유사도 스코어를 최소화하도록 최적화를 유도한다.
순수 이미지 생성을 넘어 이미지 편집, 생성기 도메인 적용, 비디오 조작, 모션 합성, 스타일 전송 및 3d 객체의 텍스처 합성을 위한 텍스트 기반 인터페이스의 사용을 탐구하는 대규모 작업이 있다.
이 논문에서는 접근방식은 개방형 조건부 합성 모델(open-ended, conditional synthesis models)을 기반으로 한다. 새로운 모델을 처음부터 훈련시키기보다는 frozen model의 어휘를 확장하고 특정 개념을 설명하는 새로운 Pword를 도입할 수 있음을 보여준다.
frozen model : 이미 학습된 모델을 가져와 사용. 데이터가 유사한 경우에는 새로운 학습 없이도 좋은 성능이 나오는데, 이런 경우 특징을 추출하는 부분의 변수는 동결하고, 분류 파트에 해당되는 fully connected layer의 변수만 업데이트 하는 방법.
2) GAN inversion
생성 네트워크로 이미지를 다루려면 종종 주어진 이미지의 해당 잠재 표현을 찾아야 하는데, 이것이 inversion이라고 하는 process이다. GAN 문헌에서 이 inversion은 최적화 기반 기술을 통해, 또는 인코더를 사용하여 수행된다. 최적화 방법은 잠재 벡터를 GAN을 통해 공급하여 대상 이미지를 다시 생성하도록 direct하게 최적화한다. 인코더는 큰 이미지 셋을 사용해서 이미지를 잠재 표현에 매핑하는 네트워크를 훈련시킨다.
저자의 작업에서는, 보이지 않는 개념에 더 잘 적용될 수 있기 때문에 최적화 접근법을 따른다. 인코더는 더욱 엄격한 일반화 요구사항을 마주하고, 동일한 자유를 제공하기 위해 웹 스케일 데이터에 대한 교육이 필요할 것이다. 저자는 GAN inversion 문헌에 비추어 임베딩 공간을 추가로 분석하여 남아있는 핵심 원칙과 그렇지 않은 원칙을 설명한다.
3) Diffusion-based inversion
Diffusion model에서 inversion은 이미지에 노이즈를 추가한 다음 네트워크를 통해 노이즈를 제거함으로써 수행된다. 그러나 이 과정은 이미지 내용을 크게 변경하게 된다. 대상 이미지에서 노이즈가 많은 low-pass filter data에 대한 노이즈 제거 프로세스를 조정하여 inversion을 개선한다. DDIM 샘플링 과정이 closed-form manner로 inverted되어 주어진 실제 이미지를 생성할 잠재 노이즈 맵을 추출할 수 있음을 보여준다. DALL-E 2에서는 이 방법을 기반으로 하며 cross-image interpolations 또는 semantic editing과 같은 이미지의 변화를 유도하는 데 사용될 수 있음을 보여준다. 후자는 CLIP 기반 코드를 사용하여 모델을 조건화하며, 다른 방법에는 적용되지 않을 수 있다.
이러한 작업은 주어진 이미지를 모델의 잠재공간으로 inversion시키는 반면, 저자는 사용자가 제공한 개념을 inversion한다. 또한 이 개념을 모델의 어휘에서 새로운 P word로 표현하여 보다 직관적이고 보편적인 편집을 가능하게 한다.
Low pass filter : 저역 통과 필터, 선택한 차단 주파수보다 낮은 주파수의 신호를 통과시키고, 더 높은 주파수의 신호는 감쇠시킴. (디지털 이미지 처리 과정에서 이미지 해상도? 쪽에 참견하는듯)
Image interpolation(이미지 보간법) : 이미지 확대 및 축소 뿐 만 아니라 비디오 시퀀스의 해상도를 증가시킬 때에 이미지를 회전시키고, 휘게 하거나 밀접히 결합하여 변환시키고 잔상을 제거하는 등 일상적으로 사용된다.
4) Personalization
모델을 특정 개인 혹은 객체에 적용하는 것은 오랜시간 머신러닝 연구에서의 목표이다. personalized(개인화)된 모델은 일반적으로 recommendation system 혹은 infederated learning에서 발견된다.
최근에는 visual과 그래픽에서도 개인화 작업을 찾을 수 있다. 특정 얼굴이나 장면을 더 잘 재구성하기 위해 생성 모델의 섬세한 tuning을 적용하는 것이 일반적이다.
PALAVRA라는 것과 저자들의 작업이 제일 관련있는데, 이것은 개인화된 객체의 검색 및 분할을 위해 사전 훈련된 CLIP 모델을 사용한다. 또한 CLIP의 text 임베딩 공간에서 특정 객체를 참조하는 Pword를 식별한다. 그런 다음 검색할 영상을 설명하거나 장면에서 특정 개체를 분할하는데 사용된다. 그러나 그들의 task와 Loss는 차별적이고, 대상을 다른 후보들로부터 분리하는 것을 목표로 한다. 결국 새로운 장면 + 재구성이나 합성에 필요한 세부사항을 capture하지 못한다.
recommendation system(추천 시스템) : 사용자의 평가와 같은 행동 양식, 또는 취향 등에 따라 사용자에게 상품을 추천해줌.
federated learning(연합 학습) : 다수의 클라이언트와 하나의 중앙 서버가 협력하여 데이터가 탈 중앙화된 상황에서 글로벌 모델 학습하는 기술. 여기서 로컬 클라이언트는 iot, 스마트폰 등을 말한다. 즉 데이터 유출없이 학습이 가능하고, 수 만개의 로컬 디바이스의 데이터를 모두 중앙서버로 전송하면 네트워크와 스토리지 비용이 증가하는데, 연합학습을 사용하면 로컬 모델의 업데이트 정보만을 주고 받으므로 커뮤니케이션 비용이 상당히 줄어들게 된다.
PALAVRA : 모든 새 탭에 마크다운 편집기를 제공, 입력한 데이터는 모든 새 탭에 저장되고 동기화되어 쉽게 메모하는데 필요한 모든 기능 제공.
3. Method
저자들의 목표는 새로운 사용자 지정 개념 언어 안내 생성을 가능하게 하는 것이다. 이를 위해 이러한 개념을 사전 훈련된 T2I 모델의 중간 표현(Intermediate representation)으로 인코딩하는 것을 목표로 한다.
Intermediate representation : 소스 코드를 표현하기 위해 컴파일러나 가상 머신에 의해 내부적으로 사용되는 데이터 구조 또는 코드. 최적화, 변환 등 추가 처리를 위해 설계되어 있다.
일반적으로 T2I 모델에 의해 사용되는 text 인코더의 단어 임베딩 단계에서 그러한 표현을 위한 후보를 검색하는 일은 자연스럽다. 거기서 이산 입력 text는 먼저 직접 최적화가 가능한 연속 벡터 표현으로 변환된다.
이전 연구에 따르면 이 임베딩 공간은 기존의 image semantics를 capture 할 수 있을 만큼 표현적이다. 그러나 이러한 접근 방식은 대조적이거나, 언어 완성 목표를 활용했으며, 두 가지 모두 이미지에 대한 심층적인 시각적 이해가 필요하지 않다.
그러나 이러한 접근 방식은 대조적이거나, language-completion objective를 활용했으며, 두 가지 모두 이미지에 대한 심층적인 시각적 이해가 필요하지 않다. 섹션 4에서 입증한 것 처럼 이러한 방법은 개념의 외형의 포착이 정확하지 않고, 합성에 이를 사용하려고 하면 상당한 시각적 변형을 일으킨다. 따라서 저자들의 목표는 비주얼 task인, 생성을 가이드 할 수 있는 P word를 찾는 것이다. 따라서 시각적 재구성 목표 (visual reconstruction objective)를 통해 P word를 찾을 것을 제안한다.
아래 내용부터는 특정 유형의 생성 모델인 LDM(Latent Diffusion Model)에 대한 접근 방식을 적용하는 핵심 세부사항을 보여준다. 섹션 5에서는 GAN inversion 문헌에서 동기를 얻은 이 접근 방식에 대한 일련의 확장을 분석한다. 그러나 나중에 보여지겠지만, 이러한 추가적인 복잡성은 여기에 제시된 초기 표현에서는 개선되지 않는다.
1) Latent Diffusion Model
저자들은 autoencoder의 latent space에서 작동하는 최근 도입된 DDPM(Denoising Diffusion Probabilistic Models) 클래스인 LDM을 통해서 구현함
LDM은 두 가지의 핵심 구성요소로 구성된다. 첫번째로는 대규모 이미지 데이터셋에서 pre-trained된 auto encoder.
이때 인코더 E는 KL-Divergence 또는 벡터의 양자화를 통해 정규화된 공간 Latent code z = E(x)에 이미지 x를 Dx로 매핑하는 방법을 학습한다. 디코더 D에서 D(E(x))는 x 값과 유사하게 된다.
KL-Divergence : 확률분포 P와 Q의 차이를 계산.
Vector Quantization(벡터 양자화) : N개의 특징 벡터 집합 x를 K개의 특징 벡터들의 집합 Y로 사상(mapping)하는 것.
두번째 구성 요소인 Diffusion model은 학습된 latent space 안에서 코드를 생성하도록 훈련된다. 이 diffusion model은 class lable, 분할된 mask, 또는 공동으로 훈련된 text 임베딩 모델의 출력에 따라 조정될 수 있다.
만약 조건화된 입력 y를 조건화에 매핑하는 모델을 C(y)라고 하면, LDM Loss는 다음과 같다.
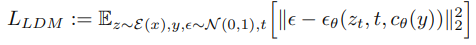
t는 time step, zt는 시간 t에 대한 Latent noise, e는 unscaled noise sample, e_세타는 denoising netwok.
직관적으로 이 식의 목적은 이미지의 latent 표현에 추가된 noise를 올바르게 제거하는 것이다.
training 동안 c_세타와 e_세타는 LDM 함수값을 최소화 하기 위해서 공동으로 최적화된다.
추론 time에는 랜덤 노이즈 텐서가 샘플링되고, 반복적으로 노이즈가 제거되어 새로운 image latent z0 를 생성한다.
최종적으로 latent code는 사전 훈련된 디코더 X = D(z0) 을 통해서 이미지로 변환된다.
저자들은 LAION-400M 데이터셋에서 사전훈련된 공개적으로 사용가능한 14억개의 매개변수 T2I 모델을 사용했다. (Stable Diffusion 썻다는 말임)
여기서 c_세타는 BERT 텍스트 인코더를 통해서 구현되며, y는 text prompt다. 다음으로 이러한 텍스트 인코더의 초기 단계와 inversion space의 선택을 검토한다.
2) Text embedding
BERT와 같은 텍스트 인코더 모델은 텍스트 프로세스 단계부터 시작한다. (Figure 2 왼쪽)
첫번째로 입력 문자열의 각 단어 또는 하위 단어는 사전 정의된 Dictionary에서 인덱스 토큰으로 변환된다.
그 다음 각 토큰은 인덱스 기반 검색을 통하여 retrieval할수 있는 고유한 임베딩 벡터에 연결된다. 이러한 임베딩 벡터들은 일반적으로 텍스트 인코더 c_세타의 일부로 학습된다.
이 작업에서 저자들은 이 임베딩 space를 inversion target으로 선택했다. 구체적으로 보자면, 학습하고자 하는 새로운 개념을 나타내기 위해 자리 표시자 문자열 S*을 지정한다. 이후 임베딩 process에 개입하고, 토큰화된 문자열과 관련 벡터를 새로운 학습된 임베딩 v*로 대체하면서 본질적으로 개념을 어휘에 주입한 것이다.
이렇게 하면서 다른단어와 마찬가지로 개념을 포함하는 새로운 문장을 구성할 수 있었다.
3) Textual Inversion
이러한 새로운 임베딩을 찾기 위해서 저자들은 작은 규모의 데이터셋(일반적으로 3~5장)을 사용하여 다양한 배경과 포즈같은 여러 설정을 거쳐 자신들의 대상 개념을 묘사했다.
작은 데이터셋에서 샘플링된 이미지에 대해 LDM 손실을 최소화 하며 직접 최적화를 통해 v*를 찾는다.
이 과정에서 생성을 조건화 하기 위해서 CLIP Imagenet 템플릿에서 파생된 neural context texts를 무작위로 샘플링한다.
최적화 목표는 다음과 같이 나타낼 수 있다.

이것은 기존의 LDM 모델과 동일한 학습 체계를 재사용하고, c_세타와 e_세타는 고정하여서 구현했다.
따라서 저자들은 학습된 임베딩이 개념에 미세한 시각적 detail을 capture 할 수 있을 것이라고 기대한다.
4) Implementation details.
별도로 언급되지 않는 한 LDM 기존 하이퍼 파라미터 선택 따름.
batch크기 4, 2*V100 GPU 사용. 기본 학습속도 0.005
모든 결과는 5000번의 최적화 step으로 생성됨.
저자들의 경우 이 매개변수가 대부분 잘 작동하는것을 발견했지만, 절대적이지는 않았다.
4. Qualitative comparisons and applications
1) Image variations

성능비교.
single Pword를 사용하여 객체의 변형을 캡쳐하고 재생성할 수 있는 능력을 보여준다. Figure 3에서 저자는 스스로의 방법을 human caption에 의해 안내되는 LDM과 human caption 또는 이미지 프롬프트에 의해 안내되는 DALL-E 2 두가지 기준선과 비교한다. 주석자들은 하나의 개념의 네 개의 이미지를 제공받고, 예술가가 그것을 재현할 수 있는 방식으로 설명하도록 요청받앗다. 짧은(12 단어를 넘지않는) 자막과 긴(30 단어를 넘지 않는)자막을 모두 요청하고, 총 10개의 캡션을 컨셉당 5개의 짧은 캡션과 5개의 긴 캡션으로 수집했다. Figure 3은 각 설정에 대해 무작위로 선택한 캡션으로 생성된 여러 결과를 보여준다. 저자는 uncurated reconstruction을 보여주는 추가적인 대규모 갤러리가 추가로 제공된다.
이러한 결과가 보여주듯이, Textual Inversion은 개념의 고유한 세부 사항을 더 잘 포착한다. human captioning은 일반적으로 물체의 가장 두드러진 특징을 잘 포착하지만, 색상 패턴(ex. 찻주전자)과 같은 더 미세한 특징을 재구성하기에는 불충분한 세부 정보를 제공한다. 어떤 경우(ex. 두개골 머그)에는 물체 자체를 자연어로 설명하기가 매우 어려울 수 있다. 이미지가 제공되면 DALL-E 2는 특히 세부 사항이 제한된, 잘 알려진 물체에 대해 더 좋은 샘플을 재현할 수 있다. 그러나 이미지 인코더(CLIP)가 보지 못했을 가능성이 높은 개인화된 개체의 고유한 세부 정보로 여전히 어려움을 겪고 있다. 그와는 다르게 Textual Inversion은 이러한 미세한 세부 사항을 성공적으로 포착할 수 있고, 단일 단어 임베딩만을 사용한다.
+ 개인적인 생각으로는 이 사진은 볼 필요가 없다고 생각하는게... 당연히 특정 사진 넣고 추가학습 시킨거랑 그냥 텍스트로만 해서 이미지 생성한거랑은 너무 큰 차이가 있지않나? textual inversion 의 성능사진 정도로만 보면 될 것 같다.
2) Text-guided synthesis
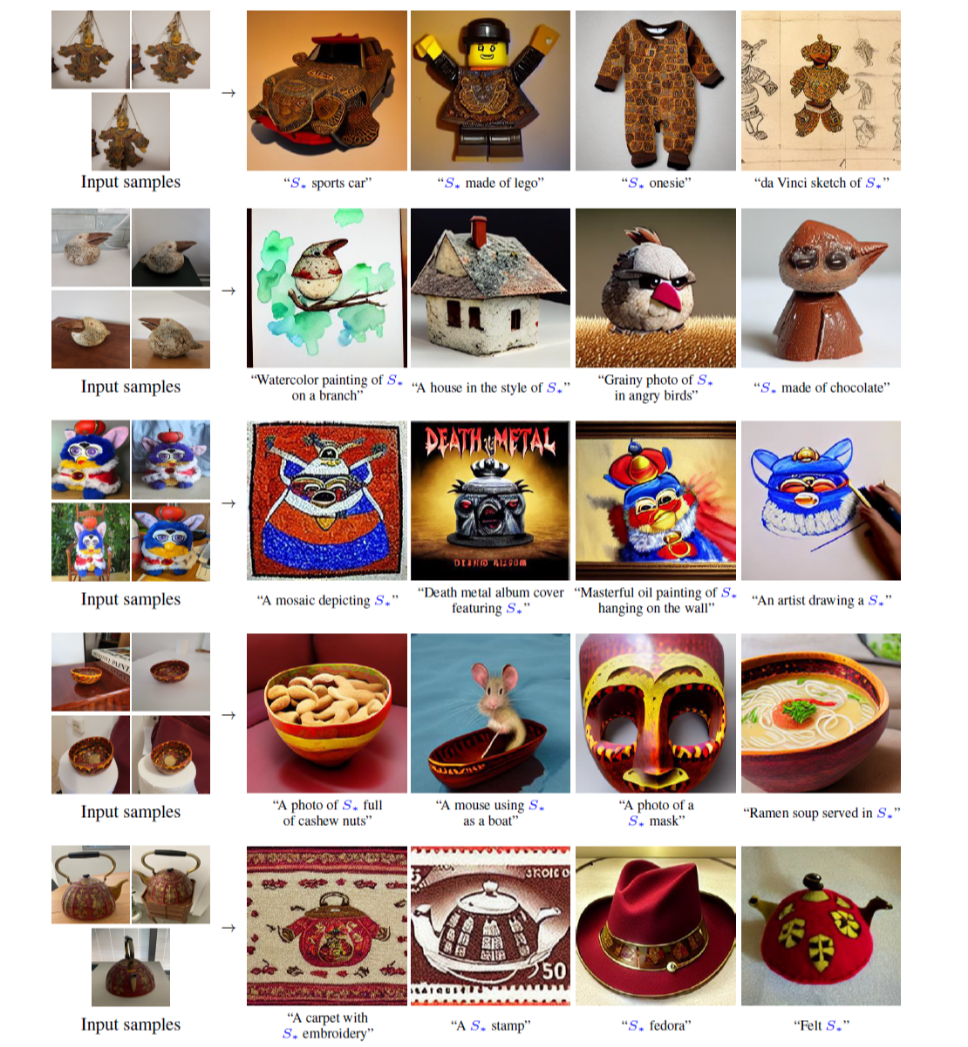
Figure 4 : 추가적인 text - guided personalized 생성 결과. 각 행에서 개념을 나타내는 이미지세트의 예시(왼쪽)와 이러한 샘플에서 파생된 P word(오른쪽)를 사용한 새로운 구성을 보여준다. 각 개념에 대해 생성된 이미지 및 조건화 텍스트의 배열과 함께 training set의 예제를 보여준다. 이러한 결과가 보여주듯이, 동결된 T2I 모델은 새로운 개념과 사전 지식의 large body 모두에 대해 공동으로 추론할 수 있으며, 이를 새로운 창조물로 통합할 수 있다. 중요한 것은 훈련 목표가 본질적으로 생성적이었음에도 불구하고, Pword는 여전히 모델이 활용할 수 있는 의미론적 개념을 캡슐화한다.

Figure 5 : 개인화된 생성 접근법과 일반적인 비교.
객체를 새로운 장면으로 구성하는 능력을 더 잘 평가하기 위해, 저자는 스스로의 방법을 여러 개인화 기준선과 비교한다(Figure 5). 특히 저자의 작업과 가장 유사한, 최근에 나온 PALAVRA를 고려하여 본다. PALAVRA는 대조 학슴 및 주기적 일관성 목표를 혼합하여 CLIP의 텍스트 임베딩 공간으로 객체 set를 인코딩한다. 저자는 그들의 접근 방식을 사용하여 새로운 유사 단어를 찾고, VQGAN-CLIP 및 CLIP-Guided Diffusion을 활용하여 새로운 이미지를 합성하는 데 사용한다. 두 번째 기준으로, 저자는 훈련 세트 이미지와 대상 텍스트(VQGAN-CLIP) 모두에 대한 CLIP-based distances를 공동으로 최소화하거나 세트의 입력 이미지(Guided Diffusion)로 최적화를 초기화하여 VQGAN-CLIP 등의 CLIP 유도 모델을 적용한다. 후자의 경우 loss를 optimization하는 과정에서 이미지 사용을 능가하는 것을 관찰하여 이미지 기반 초기화를 선택했다. Disco Diffusion에서도 비슷한 발견이 보고되었다.

스타일 보존 결과.

두개의 P word 학습 후 사용한 이미지 생성

Bias 감소
기존 모델의 경우 의사라는 단어에 남자 의사를 많이 나타냄.
Textual inversion으로 여성 의사를 추가함
5. Quantitative analysis
미지의 latent space으로의 inversion은 우리에게 가능한 설계 선택의 폭을 제공한다. 여기서, 저자는 GAN inversion 문헌에 비추어 이러한 선택을 검토하고, 많은 핵심 전제 조건(ex. distortion-editability tradeoff)가 텍스트 임베딩 공간에도 존재한다는 것을 발견한다. 그러나 저자의 분석에 따르면 GAN inversion에 일반적으로 사용되는 솔루션 중 많은 것이 이 공간에 일반화되지 못하고 도움이 되지않거나 혹은 굉장히 유해하다.
1) Evaluation metrics
잠재 공간 임베딩의 품질을 분석하기 위해 재구성과 편집 가능성의 두 가지 측면을 고려한다. 먼저 목표 개념을 복제할 수 있는 능력을 측정하고자 한다. 저자의 방법은 특정 이미지가 아닌 개념에 대한 변형을 생성하기 때문에 의미론적 CLIP-space distancs를 고려하여 유사성을 측정한다. 구체적으로 말하자면, 각 개념에 대해 "A photo of S*" 이라는 프롬프트를 사용하여 64개의 이미지를 생성한다. 이후, 저자의 reconstruction score는 생성된 이미지와 개념별 훈련 세트의 이미지 사이의 평균 쌍별 CLIP-space 코사인 유사성이다.
두 번째로, 텍스트 프롬프트를 사용하여 개념을 수정할 수 있는 능력을 평가하고자 한다. 이를 위해 다양한 난이도와 설정 프롬프트를 사용하여 이미지 세트를 생성한다. 배경 수정(ex. S*가 달에 있는 사진), 스타일 변경(ex. S*의 유화), 구성 프롬프트(ex. S*을 들고 있는 엘모)까지 다양하다.
각 프롬프트에 대해 저자는 50개의 DDIM steps를 사용하여 64개의 샘플을 합성하고, 샘플의 평균 CLIP-space embedding을 계산하고, 텍스트 프롬프트의 CLIP-space embedding과 코사인 유사성을 계산한다. 여기서 저자는 자리 표시자 S*(=A photo of on the moon)를 생략한다. 여기서 점수가 높을수록 편집 기능이 향상되고 프롬프트 자체에 대한 충실도가 높아진다. 이 논문에서의 방법은 CLIP-based 목표 점수의 직접적인 최적화를 수반하지 않으며, 따라서 적대적 점수 결함에 민감하지 않다.
2) Evaluation setups
저자는 GAN inversion에서 영감을 얻은 일련의 실험 setup을 사용하여 임베딩 공간을 평가했다 :
1. Extended latent spaces
저자는 확장된 다중 벡터 잠재 공간을 고려했다. 이 공간에서는 S*는 여러 학습된 Pword를 통해 개념을 설명하는 것과 동일한 접근 방식인 여러 pre trained된 임베딩에 내장되어 있다. 저자는 두 개와 세 개의 Pword(각각 2-world, 3-world로 표시됨)로의 확장을 고려한다. 이 설정은 단일 임베딩 벡터의 잠재적 bottleneck 현상 (병목 현상)을 완하하여 보다 정확한 재구성을 가능하게 하는 것을 목표로 한다.
bottleneck 현상(병목 현상) : 한 번에 처리할 수 있는 데이터의 양보다 처리할 수 있는 능력이 충분하지 않을 경우 CPU와 GPU에서 발생하는 문제.
2. Progressive extensions
저자는 점진적인 다중 벡터 설정을 고려한다. 여기서, 저자는 단일 임베딩 벡터로 훈련을 시작하고, 2000 training steps에 이은 두 번째 벡터와 4000 steps에 이은 세 번째 벡터를 소개한다. 이 시나리오에서는 네트워크가 먼저 핵심 세부 정보에 초점을 맞춘 다음 추가 유사 단어를 활용하여 더 세부 정보를 캡쳐할 것으로 예상된다.
3. Regularization
StyleGan 문헌에서 GAN 공간의 잠재 코드가 훈련 중 관찰된 코드 분포에 더 가까울 때 편집 가능성이 증가한다는 것을 관찰했다고 발표했다. 여기서는 학습된 임베딩을 기존 단어에 가깝게 유지하는 것을 목표로 하는 정규화 용어를 도입하여, 유사한 시나리오를 조사한다. 실제로 저자는 학습된 임베딩의 L2 거리를 객체의 coarse descriptor 임베딩까지 최소화한다. (ex. Figure 1의 "sculpture", "cat")
4. Per-image tokens
* 이 부분은 수식이 많아 패스. 대충 이야기 하자면 이미지별 고유 토큰을 지정하여 inversion 접근 방식에 도입하는 것을 이야기한다.
5. Human captions
학습된 임베딩 설정 외에도 Section 4.1에 설명된 캡션을 사용하여 human-level 성능과 비교한다. 저자는 짧은 캡션과 긴 캡션을 모두 사용하여 자리 표시자 문자열 S*을 human captions로 바꾸기만 했다.
6. Reference setups
결과의 규모와는 상관없이, 이 논문에서는 직관을 제공하기 위해 두 가지 기준을 추가했다.
첫 번째로, 프롬프트에 관계없이 항상 훈련 세트의 복사본을 생성하는 모델에서 예상되는 동작을 고려한다. 이를 위해 저자는 단순히 훈련 세트 자체를 "생성된 샘플"로 사용한다.
두 번째로, 텍스트 프롬프트에 항상 부합하지만, 개인화된 개념을 무시하는 모델을 고려한다. 저자는 evaluation prompts를 사용하여 이미지를 합성하지만, Pword는 사용하지 않는다. 이러한 설정은 각각 "Image Only"와 "Prompt Only"를 사용한다.
7. Textual-Inversion
Section 3에 설명된 대로 자체 설정을 고려한다. 저자는 학습 속도가 증가하고 (2e-2, "High-LR") 학습 속도가 감소한 (1e-4, "Low-LR") 모델을 추가로 평가한다.
8. Additional setups
추가적으로, 저자는 inversion을 위한 두 가지 추가 설정, 즉 모델 자체가 재구성을 개선하도록 최적화되는 중추적 튜닝 접근법(a pivotal tuning approach)과 DALL-E 2의 이분 반전 프로세스(bipartite inversion process)를 고려한다. 저자는 이미지 세트 크기가 재구성 및 편집 가능성에 미치는 영향을 추가로 분석했다.
3) Results
이 논문의 평가 결과는 Figure 10(a)에 요약되어 있다. 여기서 중요한 네 가지 observation을 강조하자면
1. 저자의 semantic reconstruction quality와 많은 baselines들은 훈련 세트에서 무작위 이미지를 단순히 샘플링한다는 점에서 비슷하다.
2. Single-word 방법은 유사한 reconstruction quality를 달성하고, 모든 multi-word baselines에 비해 편집 가능성을 크게 향상시킨다. 이러한 포인트는 텍스트 임베딩 공간의 impressive flexibility를 간단하게 설명하고, 단일 Pword만 사용하면서 높은 정확도로 새로운 개념을 capture 할 수 있음을 보여준다.
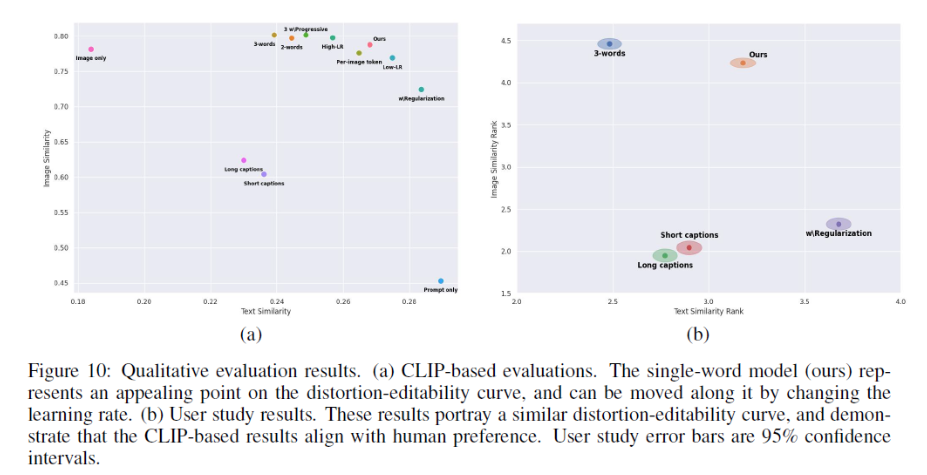
Figure 10 : Qualitative evaluation results
(a) CLIP 기반 평가 : 저자의 single-word model은 distortion-editability 곡선에서 appealing point를 나타내며, 학습 속도를 변경하여 이를 따라서 이동할 수 있다.
(b) User study 결과 : 이 결과는 유사한 결과의 distortion-editability를 나타내며, CLIP 기반 결과가 human preference와 일치한다는 것을 보여준다. user study error bar는 95%의 신뢰 구간이다.
3. 저자는 그들의 baselines이 distortion-editability trade-off 곡선을 대략적으로 설명함을 관찰했다. 여기서 실제 단어 분포에 더 가까운 임베딩(ex. 정규화, 더 적은 Pword, 또는 낮은 학습률로 인해)은 더 쉽게 수정될 수 있지만, 대상의 세부 사항을 capture하진 못한다. 이와는 다르게 단어 분포에서 멀리 벗어나는 것은 엄청나게 감소된 편집 기능의 비용으로 재구성을 개선할 수 있다. 특히 저자의 single-embedding model은 단순히 학습 속도를 변경함으로써 이 곡선을 따라 이동할 수 있으며, 이 trade-off에 대한 제어 수준을 사용자에게 제공했다.
distortion-editability trade-off : 원본에 가깝게 만들수록 editability가 떨어진다.
distortion : 얼마나 reference 이미지와 다른지
perception : 얼마나 realistic한지
editability : 얼마나 자연스럽게 editing 되는지
4. 저자는 개념에 대한 인간의 설명이 유사성을 포착하는 데 실패할 뿐만 아니라 편집 가능성 역시 저하된다는 점에 주목했다. 저자는 이것이 비전 및 언어 모델이 의미론적으로 의미 있는 토큰의 하위 집합에 초점을 맞추는 경향이 있는, selective similarity property 과 관련이 있다고 가정한다. 긴 캡션을 사용하여 모델이 객체 설명 자체에만 초점을 맞추고, 원하는 설정을 무시할 가능성을 높인다. 이 논문의 모델은 단일 토큰만을 사용하기 때문에 이러한 위험을 최소화 할 수 있다.
마지막으로 저자는 재구성 점수가 무작위로 샘플링된 실제 이미지의 점수와 동등하지만, 이러한 결과는 사소하게 취급해야 한다고 했다.



