Open AI Glide: Text-to image Generation Explained with code 따라해보기
Text to image code를 실행해보고 싶었는데 DALL2같은 경우는 코드 봐도 모르겠고... 해서 열심히 구글링하다가 찾은 영상
영상에 들어가서 더보기란 누르면 깃허브 주소가 있다
이 영상 따라서 Google Colab GPU에서 실행
*처음에 설정을 깜빡하고 안해서 CPU에서 진행했는데 거의 진행속도가 10배이상 차이났다.
무조건 GPU로 설정 후에 하는거 추천!
GitHub - openai/glide-text2im: GLIDE: a diffusion-based text-conditional image synthesis model
GitHub - openai/glide-text2im: GLIDE: a diffusion-based text-conditional image synthesis model
GLIDE: a diffusion-based text-conditional image synthesis model - GitHub - openai/glide-text2im: GLIDE: a diffusion-based text-conditional image synthesis model
github.com
깃허브 주소에 들어가서 코드들을 전부 보는데... 유투브 영상과 같은 코드가 없었다 뭔가 조금씩 다 달랐음
그래서 유툽영상 코드를 하나하나(ㅋㅋ) 입력하면서 따라했는데
# Create base model.
options = model_and_diffusion_defaults()
options['use_fp16'] = has_cuda
options['timestep_respacing'] = '100' # use 100 diffusion steps for fast sampling
model, diffusion = create_model_and_diffusion(**options)
model.eval()
if has_cuda:
model.convert_to_fp16()
model.to(device)
model.load_state_dict(load_checkpoint('base', device))
print('total base parameters', sum(x.numel() for x in model.parameters()))여기서 막힘 options 모델을 찾을수 없다 어쩌구
보니까 torch.nn코드도 좀 다르고 뭔가 달랐음 코드가.....................
그래서 그냥 youtube 영상을 버리고
glide-text2im/notebooks/clip_guided.ipynb 코드만 전부 따라함
처음부터 다시시작해야됨
clip부분에서 코드가 달라서 실패한듯 추가로 분석할거임
나머지 진행부분은 그냥 유툽이랑 똑같이 진행 (ex.진행바 같은거)

맨처음 예시 코드에 적혀있던 그대로 코기 오일페인팅 출력
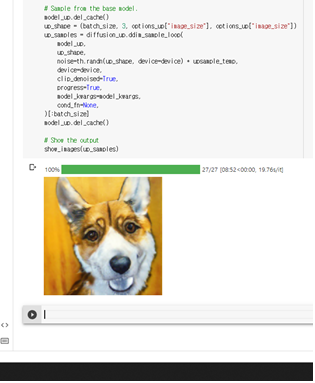
64*64로 확대하는 코드 실행
*코드 분석을 하지 않고 무작정 실행만 한 상태라 64*64코드만 돌려도 결과가 출력될거라고 생각함
!!!!!!!!!!!!!!!안됨!!!!!!!!!!!!!!!
무조건 위에 코드부터 돌려야된다
코드 분석하면서 확인해볼 예정
그상태에서
# Sampling parameters
prompt = "ㅇㅇㅇㅇㅇㅇㅇㅇㅇㅇㅇㅇ"
batch_size = 1
guidance_scale = 3.0
# Tune this parameter to control the sharpness of 256x256 images.
# A value of 1.0 is sharper, but sometimes results in grainy artifacts.
upsample_temp = 0.997저 코드에서 ㅇㅇㅇㅇ 있는 부분을 계속해서 바꿔서 진행함
<결과물^^..>
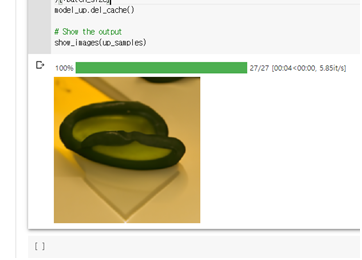
선글라스를 쓴 오이를 출력...
이거는 Google imagen 자료 찾다가 선인자이 선글라스 쓴 img를 보고 귀여워서 참고해서 입력했는데
나만 이상한 사람이지...........^^?

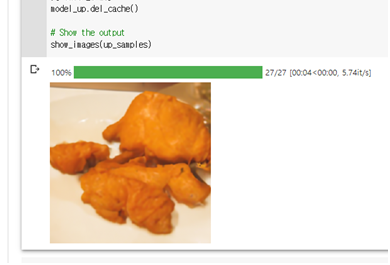
좀 흥미로운 결과 물런 결과값이 맘에 든다는건 아님
fried / chicken / swimming
같은 단어가 들어갔음에도 불구하고 다른 결과값이 나옴 비슷하긴 하지만
단어의 순서나 be동사에게 영향을 받는다는 걸 알 수 있음
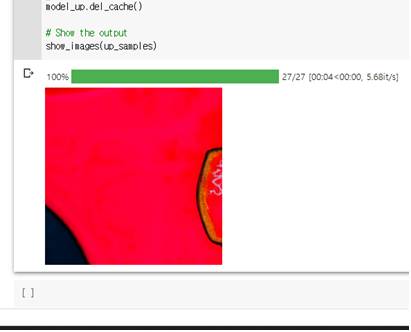

결과값이 막막하지만 분석해보자...
jean이 청바지라고 생각하고 red jean 이라고 텍스트를 입력하자 이상한 무슨..세포같이 나옴
혹시나 해서 사전예문을 확인하니까 대부분의 청바지는 jeans로 부름 ㅎㅎ 영어 공부 열심히 하겠습니다
그래서 jeans로 바꿧더니 청바지 같진 않아도 대충 바지의 형태를 보이는 그림이 등장
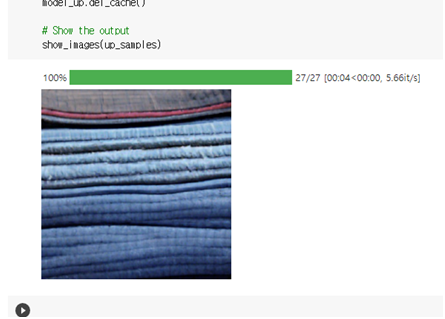
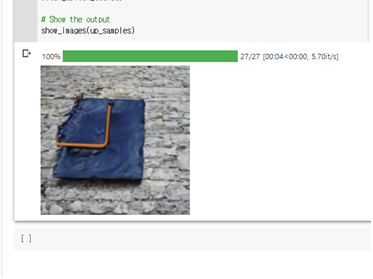
jean이 무엇을 의미하나 싶어서 jean과 jeans를 각각 입력함
jeans 를 입력했을 땐 여러개의 청바지가 겹쳐져 있는 것처럼 나와서 jean 을 다시 입력함
그랫더니 바지인지 뭔지 모를 것이 등장
인공지능은 어렵다.. 코드 분석해서 다시 정리해야지